mirror of
https://github.com/VictoriaMetrics/VictoriaMetrics.git
synced 2026-05-23 19:56:31 +03:00
Compare commits
1 Commits
make/use-g
...
9074
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6768a34858 |
11
Makefile
11
Makefile
@@ -528,6 +528,8 @@ vet:
|
||||
|
||||
check-all: fmt vet golangci-lint govulncheck
|
||||
|
||||
clean-checkers: remove-golangci-lint remove-govulncheck
|
||||
|
||||
test:
|
||||
GOEXPERIMENT=synctest go test ./lib/... ./app/...
|
||||
|
||||
@@ -572,11 +574,12 @@ app-local-goos-goarch:
|
||||
app-local-windows-goarch:
|
||||
CGO_ENABLED=0 GOOS=windows GOARCH=$(GOARCH) go build $(RACE) -ldflags "$(GO_BUILDINFO)" -o bin/$(APP_NAME)-windows-$(GOARCH)$(RACE).exe $(PKG_PREFIX)/app/$(APP_NAME)
|
||||
|
||||
quicktemplate-gen:
|
||||
go tool qtc
|
||||
quicktemplate-gen: install-qtc
|
||||
qtc
|
||||
|
||||
install-qtc:
|
||||
which qtc || go install github.com/valyala/quicktemplate/qtc@latest
|
||||
|
||||
golangci-lint:
|
||||
GOEXPERIMENT=synctest go tool golangci-lint run
|
||||
|
||||
golangci-lint: install-golangci-lint
|
||||
GOEXPERIMENT=synctest golangci-lint run
|
||||
|
||||
@@ -101,11 +101,9 @@ func (lr *LineReader) readMoreData() bool {
|
||||
|
||||
bufLen := len(lr.buf)
|
||||
if bufLen >= MaxLineSizeBytes.IntN() {
|
||||
ok, skippedBytes := lr.skipUntilNextLine()
|
||||
logger.Warnf("%s: the line length exceeds -insert.maxLineSizeBytes=%d; skipping it; total skipped bytes=%d",
|
||||
lr.name, MaxLineSizeBytes.IntN(), skippedBytes)
|
||||
logger.Warnf("%s: the line length exceeds -insert.maxLineSizeBytes=%d; skipping it; line contents=%q", lr.name, MaxLineSizeBytes.IntN(), lr.buf)
|
||||
tooLongLinesSkipped.Inc()
|
||||
return ok
|
||||
return lr.skipUntilNextLine()
|
||||
}
|
||||
|
||||
lr.buf = slicesutil.SetLength(lr.buf, MaxLineSizeBytes.IntN())
|
||||
@@ -123,35 +121,26 @@ func (lr *LineReader) readMoreData() bool {
|
||||
|
||||
var tooLongLinesSkipped = metrics.NewCounter("vl_too_long_lines_skipped_total")
|
||||
|
||||
func (lr *LineReader) skipUntilNextLine() (bool, int) {
|
||||
|
||||
// Initialize skipped bytes count with MaxLineSizeBytes because
|
||||
// we've already read that many bytes without encountering a newline,
|
||||
// indicating the line size exceeds the maximum allowed limit.
|
||||
skipSizeBytes := MaxLineSizeBytes.IntN()
|
||||
|
||||
func (lr *LineReader) skipUntilNextLine() bool {
|
||||
for {
|
||||
lr.buf = slicesutil.SetLength(lr.buf, MaxLineSizeBytes.IntN())
|
||||
n, err := lr.r.Read(lr.buf)
|
||||
skipSizeBytes += n
|
||||
lr.buf = lr.buf[:n]
|
||||
if err != nil {
|
||||
if errors.Is(err, io.EOF) {
|
||||
lr.eofReached = true
|
||||
lr.buf = lr.buf[:0]
|
||||
return true, skipSizeBytes
|
||||
return true
|
||||
}
|
||||
lr.err = fmt.Errorf("cannot skip the current line: %s", err)
|
||||
return false, skipSizeBytes
|
||||
return false
|
||||
}
|
||||
if n := bytes.IndexByte(lr.buf, '\n'); n >= 0 {
|
||||
// Include skipped bytes before \n, including the newline itself.
|
||||
skipSizeBytes += n + 1 - len(lr.buf)
|
||||
// Include \n in the buf, so too long line is replaced with an empty line.
|
||||
// This is needed for maintaining synchorinzation consistency between lines
|
||||
// in protocols such as Elasticsearch bulk import.
|
||||
lr.buf = append(lr.buf[:0], lr.buf[n:]...)
|
||||
return true, skipSizeBytes
|
||||
return true
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
package internalinsert
|
||||
|
||||
import (
|
||||
"flag"
|
||||
"fmt"
|
||||
"net/http"
|
||||
"time"
|
||||
@@ -17,11 +18,17 @@ import (
|
||||
)
|
||||
|
||||
var (
|
||||
disableInsert = flag.Bool("internalinsert.disable", false, "Whether to disable /internal/insert HTTP endpoint")
|
||||
maxRequestSize = flagutil.NewBytes("internalinsert.maxRequestSize", 64*1024*1024, "The maximum size in bytes of a single request, which can be accepted at /internal/insert HTTP endpoint")
|
||||
)
|
||||
|
||||
// RequestHandler processes /internal/insert requests.
|
||||
func RequestHandler(w http.ResponseWriter, r *http.Request) {
|
||||
if *disableInsert {
|
||||
httpserver.Errorf(w, r, "requests to /internal/insert are disabled with -internalinsert.disable command-line flag")
|
||||
return
|
||||
}
|
||||
|
||||
startTime := time.Now()
|
||||
if r.Method != "POST" {
|
||||
w.WriteHeader(http.StatusMethodNotAllowed)
|
||||
|
||||
@@ -1,7 +1,6 @@
|
||||
package vlinsert
|
||||
|
||||
import (
|
||||
"flag"
|
||||
"fmt"
|
||||
"net/http"
|
||||
"strings"
|
||||
@@ -14,12 +13,6 @@ import (
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vlinsert/loki"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vlinsert/opentelemetry"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vlinsert/syslog"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/httpserver"
|
||||
)
|
||||
|
||||
var (
|
||||
disableInsert = flag.Bool("insert.disable", false, "Whether to disable /insert/* HTTP endpoints")
|
||||
disableInternal = flag.Bool("internalinsert.disable", false, "Whether to disable /internal/insert HTTP endpoint")
|
||||
)
|
||||
|
||||
// Init initializes vlinsert
|
||||
@@ -34,31 +27,19 @@ func Stop() {
|
||||
|
||||
// RequestHandler handles insert requests for VictoriaLogs
|
||||
func RequestHandler(w http.ResponseWriter, r *http.Request) bool {
|
||||
path := strings.ReplaceAll(r.URL.Path, "//", "/")
|
||||
|
||||
if strings.HasPrefix(path, "/insert/") {
|
||||
if *disableInsert {
|
||||
httpserver.Errorf(w, r, "requests to /insert/* are disabled with -insert.disable command-line flag")
|
||||
return true
|
||||
}
|
||||
|
||||
return insertHandler(w, r, path)
|
||||
}
|
||||
path := r.URL.Path
|
||||
|
||||
if path == "/internal/insert" {
|
||||
if *disableInternal || *disableInsert {
|
||||
httpserver.Errorf(w, r, "requests to /internal/insert are disabled with -internalinsert.disable or -insert.disable command-line flag")
|
||||
return true
|
||||
}
|
||||
internalinsert.RequestHandler(w, r)
|
||||
return true
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
func insertHandler(w http.ResponseWriter, r *http.Request, path string) bool {
|
||||
if !strings.HasPrefix(path, "/insert/") {
|
||||
// Skip requests, which do not start with /insert/, since these aren't our requests.
|
||||
return false
|
||||
}
|
||||
path = strings.TrimPrefix(path, "/insert")
|
||||
path = strings.ReplaceAll(path, "//", "/")
|
||||
|
||||
switch path {
|
||||
case "/jsonline":
|
||||
@@ -88,7 +69,7 @@ func insertHandler(w http.ResponseWriter, r *http.Request, path string) bool {
|
||||
case strings.HasPrefix(path, "/datadog/"):
|
||||
path = strings.TrimPrefix(path, "/datadog")
|
||||
return datadog.RequestHandler(path, w, r)
|
||||
default:
|
||||
return false
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
@@ -2,6 +2,7 @@ package internalselect
|
||||
|
||||
import (
|
||||
"context"
|
||||
"flag"
|
||||
"fmt"
|
||||
"net/http"
|
||||
"strconv"
|
||||
@@ -21,8 +22,15 @@ import (
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/netutil"
|
||||
)
|
||||
|
||||
var disableSelect = flag.Bool("internalselect.disable", false, "Whether to disable /internal/select/* HTTP endpoints")
|
||||
|
||||
// RequestHandler processes requests to /internal/select/*
|
||||
func RequestHandler(ctx context.Context, w http.ResponseWriter, r *http.Request) {
|
||||
if *disableSelect {
|
||||
httpserver.Errorf(w, r, "requests to /internal/select/* are disabled with -internalselect.disable command-line flag")
|
||||
return
|
||||
}
|
||||
|
||||
startTime := time.Now()
|
||||
|
||||
path := r.URL.Path
|
||||
|
||||
@@ -25,9 +25,6 @@ var (
|
||||
maxQueueDuration = flag.Duration("search.maxQueueDuration", 10*time.Second, "The maximum time the search request waits for execution when -search.maxConcurrentRequests "+
|
||||
"limit is reached; see also -search.maxQueryDuration")
|
||||
maxQueryDuration = flag.Duration("search.maxQueryDuration", time.Second*30, "The maximum duration for query execution. It can be overridden to a smaller value on a per-query basis via 'timeout' query arg")
|
||||
|
||||
disableSelect = flag.Bool("select.disable", false, "Whether to disable /select/* HTTP endpoints")
|
||||
disableInternal = flag.Bool("internalselect.disable", false, "Whether to disable /internal/select/* HTTP endpoints")
|
||||
)
|
||||
|
||||
func getDefaultMaxConcurrentRequests() int {
|
||||
@@ -74,31 +71,13 @@ var vmuiFileServer = http.FileServer(http.FS(vmuiFiles))
|
||||
|
||||
// RequestHandler handles select requests for VictoriaLogs
|
||||
func RequestHandler(w http.ResponseWriter, r *http.Request) bool {
|
||||
path := strings.ReplaceAll(r.URL.Path, "//", "/")
|
||||
path := r.URL.Path
|
||||
|
||||
if strings.HasPrefix(path, "/select/") {
|
||||
if *disableSelect {
|
||||
httpserver.Errorf(w, r, "requests to /select/* are disabled with -select.disable command-line flag")
|
||||
return true
|
||||
}
|
||||
|
||||
return selectHandler(w, r, path)
|
||||
if !strings.HasPrefix(path, "/select/") && !strings.HasPrefix(path, "/internal/select/") {
|
||||
// Skip requests, which do not start with /select/, since these aren't our requests.
|
||||
return false
|
||||
}
|
||||
|
||||
if strings.HasPrefix(path, "/internal/select/") {
|
||||
if *disableInternal || *disableSelect {
|
||||
httpserver.Errorf(w, r, "requests to /internal/select/* are disabled with -internalselect.disable or -select.disable command-line flag")
|
||||
return true
|
||||
}
|
||||
internalselect.RequestHandler(r.Context(), w, r)
|
||||
return true
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
func selectHandler(w http.ResponseWriter, r *http.Request, path string) bool {
|
||||
ctx := r.Context()
|
||||
path = strings.ReplaceAll(path, "//", "/")
|
||||
|
||||
if path == "/select/vmui" {
|
||||
// VMUI access via incomplete url without `/` in the end. Redirect to complete url.
|
||||
@@ -121,6 +100,7 @@ func selectHandler(w http.ResponseWriter, r *http.Request, path string) bool {
|
||||
return true
|
||||
}
|
||||
|
||||
ctx := r.Context()
|
||||
if path == "/select/logsql/tail" {
|
||||
logsqlTailRequests.Inc()
|
||||
// Process live tailing request without timeout, since it is OK to run live tailing requests for very long time.
|
||||
@@ -140,6 +120,13 @@ func selectHandler(w http.ResponseWriter, r *http.Request, path string) bool {
|
||||
}
|
||||
defer decRequestConcurrency()
|
||||
|
||||
if strings.HasPrefix(path, "/internal/select/") {
|
||||
// Process internal request from vlselect without timeout (e.g. use ctx instead of ctxWithTimeout),
|
||||
// since the timeout must be controlled by the vlselect.
|
||||
internalselect.RequestHandler(ctx, w, r)
|
||||
return true
|
||||
}
|
||||
|
||||
ok := processSelectRequest(ctxWithTimeout, w, r, path)
|
||||
if !ok {
|
||||
return false
|
||||
|
||||
@@ -120,9 +120,6 @@ func normalizeURL(uOrig *url.URL) *url.URL {
|
||||
u := *uOrig
|
||||
// Prevent from attacks with using `..` in r.URL.Path
|
||||
u.Path = path.Clean(u.Path)
|
||||
if u.Path == "." {
|
||||
u.Path = "/"
|
||||
}
|
||||
if !strings.HasSuffix(u.Path, "/") && strings.HasSuffix(uOrig.Path, "/") {
|
||||
// The path.Clean() removes trailing slash.
|
||||
// Return it back if needed.
|
||||
|
||||
@@ -128,40 +128,7 @@ func TestCreateTargetURLSuccess(t *testing.T) {
|
||||
// Simple routing with `url_prefix`
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar"),
|
||||
}, "", "http://foo.bar", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar"),
|
||||
}, "/", "http://foo.bar", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar"),
|
||||
}, "http://aaa///", "http://foo.bar", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/"),
|
||||
}, "/", "http://foo.bar/", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/"),
|
||||
}, "/x", "http://foo.bar/x", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/"),
|
||||
}, "/x/", "http://foo.bar/x/", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/"),
|
||||
}, "http://abc///x/", "http://foo.bar/x/", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/"),
|
||||
}, "http://foo//x", "http://foo.bar/x", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/baz"),
|
||||
}, "", "http://foo.bar/baz", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/baz"),
|
||||
}, "/", "http://foo.bar/baz", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/x/"),
|
||||
}, "/abc", "http://foo.bar/x/abc", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/x/"),
|
||||
}, "/abc/", "http://foo.bar/x/abc/", "", "", nil, "least_loaded", 0)
|
||||
}, "", "http://foo.bar/.", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar"),
|
||||
HeadersConf: HeadersConf{
|
||||
@@ -182,12 +149,6 @@ func TestCreateTargetURLSuccess(t *testing.T) {
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar"),
|
||||
}, "a/b?c=d", "http://foo.bar/a/b?c=d", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar"),
|
||||
}, "/a/b?c=d", "http://foo.bar/a/b?c=d", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("http://foo.bar/"),
|
||||
}, "/a/b?c=d", "http://foo.bar/a/b?c=d", "", "", nil, "least_loaded", 0)
|
||||
f(&UserInfo{
|
||||
URLPrefix: mustParseURL("https://sss:3894/x/y"),
|
||||
}, "/z", "https://sss:3894/x/y/z", "", "", nil, "least_loaded", 0)
|
||||
|
||||
@@ -19,7 +19,6 @@ import (
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmctl/barpool"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmctl/native"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmctl/remoteread"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/netutil"
|
||||
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmctl/influx"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmctl/opentsdb"
|
||||
@@ -45,7 +44,6 @@ func main() {
|
||||
if c.Bool(globalDisableProgressBar) {
|
||||
barpool.Disable(true)
|
||||
}
|
||||
netutil.EnableIPv6()
|
||||
return nil
|
||||
}
|
||||
app := &cli.App{
|
||||
|
||||
@@ -5,10 +5,8 @@ import (
|
||||
"strings"
|
||||
"unsafe"
|
||||
|
||||
"github.com/VictoriaMetrics/metricsql"
|
||||
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmselect/netstorage"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/atomicutil"
|
||||
"github.com/VictoriaMetrics/metricsql"
|
||||
)
|
||||
|
||||
// callbacks for optimized incremental calculations for aggregate functions
|
||||
@@ -68,8 +66,9 @@ var incrementalAggrFuncCallbacksMap = map[string]*incrementalAggrFuncCallbacks{
|
||||
type incrementalAggrContextMap struct {
|
||||
m map[string]*incrementalAggrContext
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [atomicutil.CacheLineSize - unsafe.Sizeof(map[string]*incrementalAggrContext{})%atomicutil.CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with
|
||||
// 128 mod (cache line size) = 0 .
|
||||
_ [128 - unsafe.Sizeof(map[string]*incrementalAggrContext{})%128]byte
|
||||
}
|
||||
|
||||
type incrementalAggrFuncContext struct {
|
||||
|
||||
@@ -17,7 +17,6 @@ import (
|
||||
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmselect/netstorage"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/app/vmselect/searchutil"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/atomicutil"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/bytesutil"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/cgroup"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/decimal"
|
||||
@@ -1886,8 +1885,9 @@ func doRollupForTimeseries(funcName string, keepMetricNames bool, rc *rollupConf
|
||||
type timeseriesWithPadding struct {
|
||||
tss []*timeseries
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [atomicutil.CacheLineSize - unsafe.Sizeof([]*timeseries{})%atomicutil.CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with
|
||||
// 128 mod (cache line size) = 0 .
|
||||
_ [128 - unsafe.Sizeof([]*timeseries{})%128]byte
|
||||
}
|
||||
|
||||
type timeseriesByWorkerID struct {
|
||||
|
||||
@@ -10,8 +10,6 @@ import { useSearchParams } from "react-router-dom";
|
||||
import throttle from "lodash/throttle";
|
||||
import GroupLogsItem from "../../../GroupLogs/GroupLogsItem";
|
||||
import LiveTailingSettings from "./LiveTailingSettings";
|
||||
import Alert from "../../../../../components/Main/Alert/Alert";
|
||||
import { isDecreasing } from "../../../../../utils/array";
|
||||
|
||||
const SCROLL_THRESHOLD = 100;
|
||||
const scrollToBottom = () => window.scrollTo({
|
||||
@@ -38,8 +36,7 @@ const LiveTailingView: FC<ViewProps> = ({ settingsRef }) => {
|
||||
stopLiveTailing,
|
||||
pauseLiveTailing,
|
||||
resumeLiveTailing,
|
||||
clearLogs,
|
||||
isLimitedLogsPerUpdate
|
||||
clearLogs
|
||||
} = useLiveTailingLogs(query, rowsPerPage);
|
||||
|
||||
const displayFieldsString = searchParams.get(LOGS_URL_PARAMS.DISPLAY_FIELDS) || LOGS_DISPLAY_FIELDS;
|
||||
@@ -67,17 +64,13 @@ const LiveTailingView: FC<ViewProps> = ({ settingsRef }) => {
|
||||
const container = containerRef.current;
|
||||
if (!container) return;
|
||||
|
||||
let prevScrollTop: number[] = [];
|
||||
const handleScroll = () => {
|
||||
const { scrollTop, scrollHeight, clientHeight } = document.documentElement;
|
||||
const isBottom = Math.abs(scrollHeight - scrollTop - clientHeight) < SCROLL_THRESHOLD;
|
||||
|
||||
setIsAtBottom(isBottom);
|
||||
prevScrollTop.push(scrollTop);
|
||||
prevScrollTop = prevScrollTop.slice(-3);
|
||||
const isMoveToTop = isDecreasing(prevScrollTop);
|
||||
|
||||
if (!isBottom && !isPaused && isMoveToTop) {
|
||||
if (!isBottom && !isPaused) {
|
||||
pauseLiveTailing();
|
||||
}
|
||||
};
|
||||
@@ -96,6 +89,8 @@ const LiveTailingView: FC<ViewProps> = ({ settingsRef }) => {
|
||||
handleResumeLiveTailing();
|
||||
}, [rowsPerPage]);
|
||||
|
||||
|
||||
|
||||
if (error) {
|
||||
return <div className="vm-live-tailing-view__error">{error}</div>;
|
||||
}
|
||||
@@ -143,7 +138,6 @@ const LiveTailingView: FC<ViewProps> = ({ settingsRef }) => {
|
||||
</div>
|
||||
)}
|
||||
</div>
|
||||
{isLimitedLogsPerUpdate && (<Alert variant="warning">Too many logs per second detected. Large volumes of log data are difficult to process and may impact performance. We recommend adding filters to your query for better analysis and system performance.</Alert>)}
|
||||
</>
|
||||
);
|
||||
};
|
||||
|
||||
@@ -34,9 +34,9 @@
|
||||
width: 100%;
|
||||
height: 100%;
|
||||
overflow: auto;
|
||||
padding: $padding-global;
|
||||
min-height: 200px;
|
||||
font-family: $font-family-monospace;
|
||||
padding-bottom: $padding-medium;
|
||||
}
|
||||
|
||||
&__empty {
|
||||
|
||||
@@ -1,147 +0,0 @@
|
||||
import { act, renderHook } from "@testing-library/preact";
|
||||
import { useLiveTailingLogs } from "./useLiveTailingLogs";
|
||||
import { vi } from "vitest";
|
||||
|
||||
vi.mock("../../../../../state/common/StateContext", () => ({
|
||||
useAppState: () => ({ serverUrl: "http://localhost:8080" }),
|
||||
}));
|
||||
|
||||
vi.mock("../../../../../hooks/useTenant", () => ({
|
||||
useTenant: () => ({}),
|
||||
}));
|
||||
|
||||
// Mock dependencies
|
||||
const mockFetch = vi.fn();
|
||||
global.fetch = mockFetch;
|
||||
|
||||
const createMockStreamResponse = (logs: string[], sendCount: number = 1) => ({
|
||||
ok: true,
|
||||
body: new ReadableStream({
|
||||
async start(controller) {
|
||||
for (let i = 0; i < sendCount; i++) {
|
||||
logs.forEach((log) => {
|
||||
controller.enqueue(new TextEncoder().encode(log + "\n"));
|
||||
});
|
||||
await new Promise((resolve) => setTimeout(resolve, 1000));
|
||||
}
|
||||
|
||||
controller.close();
|
||||
},
|
||||
}),
|
||||
text: async () => logs.join("\n"),
|
||||
});
|
||||
|
||||
describe("useLiveTailingLogs", () => {
|
||||
afterEach(() => {
|
||||
vi.restoreAllMocks();
|
||||
vi.clearAllMocks();
|
||||
});
|
||||
|
||||
it("should start live tailing and process logs", async () => {
|
||||
const query = "*";
|
||||
const limit = 10;
|
||||
const { result } = renderHook(() => useLiveTailingLogs(query, limit));
|
||||
|
||||
mockFetch.mockResolvedValue(createMockStreamResponse(["{\"logs\":\"test log\"}"]));
|
||||
|
||||
await act(async () => {
|
||||
const started = await result.current.startLiveTailing();
|
||||
expect(started).toBe(true);
|
||||
});
|
||||
|
||||
expect(mockFetch).toHaveBeenCalledTimes(1);
|
||||
expect(mockFetch).toHaveBeenCalledWith(
|
||||
"http://localhost:8080/select/logsql/tail",
|
||||
expect.objectContaining({
|
||||
method: "POST",
|
||||
body: new URLSearchParams({
|
||||
query: query.trim(),
|
||||
}),
|
||||
})
|
||||
);
|
||||
});
|
||||
|
||||
it("should pause and resume live tailing", () => {
|
||||
const query = "*";
|
||||
const limit = 10;
|
||||
const { result } = renderHook(() => useLiveTailingLogs(query, limit));
|
||||
|
||||
act(() => {
|
||||
result.current.pauseLiveTailing();
|
||||
});
|
||||
|
||||
expect(result.current.isPaused).toBe(true);
|
||||
|
||||
act(() => {
|
||||
result.current.resumeLiveTailing();
|
||||
});
|
||||
|
||||
expect(result.current.isPaused).toBe(false);
|
||||
});
|
||||
|
||||
it("should stop live tailing", async () => {
|
||||
const query = "*";
|
||||
const limit = 10;
|
||||
const { result } = renderHook(() => useLiveTailingLogs(query, limit));
|
||||
|
||||
act(() => {
|
||||
result.current.stopLiveTailing();
|
||||
});
|
||||
|
||||
expect(result.current.logs).toHaveLength(0);
|
||||
});
|
||||
|
||||
it("should clear logs", () => {
|
||||
const query = "*";
|
||||
const limit = 10;
|
||||
const { result } = renderHook(() => useLiveTailingLogs(query, limit));
|
||||
|
||||
act(() => {
|
||||
result.current.clearLogs();
|
||||
});
|
||||
|
||||
expect(result.current.logs).toEqual([]);
|
||||
});
|
||||
|
||||
it("should handle errors during live tailing", async () => {
|
||||
const query = "*";
|
||||
const limit = 10;
|
||||
const { result } = renderHook(() => useLiveTailingLogs(query, limit));
|
||||
|
||||
mockFetch.mockRejectedValue(new Error("Network error"));
|
||||
|
||||
await act(async () => {
|
||||
const started = await result.current.startLiveTailing();
|
||||
expect(started).toBe(false);
|
||||
});
|
||||
|
||||
expect(result.current.error).toBe("Error: Network error");
|
||||
expect(result.current.logs).toHaveLength(0);
|
||||
});
|
||||
|
||||
it("should process high load of logs incoming at 100k logs per second", async () => {
|
||||
const query = "*";
|
||||
const limit = 1000;
|
||||
const logCount = 10000; // High log rate
|
||||
const logs = Array.from({ length: logCount }, (_, i) => `{"log": "log message ${i}"}`);
|
||||
const { result } = renderHook(() => useLiveTailingLogs(query, limit));
|
||||
|
||||
mockFetch.mockResolvedValue(createMockStreamResponse(logs, 7));
|
||||
|
||||
await act(async () => {
|
||||
const started = await result.current.startLiveTailing();
|
||||
expect(started).toBe(true);
|
||||
});
|
||||
|
||||
// Wait for logs to process
|
||||
await new Promise((resolve) => setTimeout(resolve, 7000));
|
||||
|
||||
// Verify logs are limited and processed correctly
|
||||
expect(result.current.logs.length).toBeLessThanOrEqual(limit);
|
||||
// After setting flag isLimitedLogsPerUpdate when more than 200 logs received 5 times in a row,
|
||||
// we take only the last 200 logs, so we get 800 older logs (9200 - 9999) and 200 new logs (9800-9999)
|
||||
expect(result.current.logs[0].log).toStrictEqual("log message 9200");
|
||||
expect(result.current.logs[799].log).toStrictEqual("log message 9999");
|
||||
expect(result.current.isLimitedLogsPerUpdate).toBeTruthy();
|
||||
}, { timeout: 9000 });
|
||||
});
|
||||
@@ -2,161 +2,22 @@ import { useCallback, useEffect, useRef, useState } from "preact/compat";
|
||||
import { ErrorTypes } from "../../../../../types";
|
||||
import { Logs } from "../../../../../api/types";
|
||||
import { useAppState } from "../../../../../state/common/StateContext";
|
||||
import { useSearchParams } from "react-router-dom";
|
||||
import useBoolean from "../../../../../hooks/useBoolean";
|
||||
import { useTenant } from "../../../../../hooks/useTenant";
|
||||
|
||||
/**
|
||||
* Defines the maximum number of consecutive times logs can be fetched above the threshold
|
||||
* before showing a warning notification, and vice versa:
|
||||
* - If logs are fetched above a threshold this many times in a row -> show warning
|
||||
* - If warning is shown, it won't disappear until logs are fetched below a threshold
|
||||
* this many times in a row
|
||||
*
|
||||
* This threshold helps optimize log display performance when dealing with large volumes of logs.
|
||||
* If the threshold is consistently exceeded, users will be prompted to add filters to their query
|
||||
* for better system performance and more focused log analysis.
|
||||
*/
|
||||
const MAX_ATTEMPTS_FETCH_LOGS_PER_SECOND = 5;
|
||||
/**
|
||||
* Defines the log's threshold, after which will be shown a warning notification
|
||||
*/
|
||||
const LOGS_THRESHOLD = 200;
|
||||
const CONNECTION_TIMEOUT_MS = 5000;
|
||||
const PROCESSING_INTERVAL_MS = 1000;
|
||||
|
||||
const createStreamProcessor = (
|
||||
bufferRef: React.MutableRefObject<string>,
|
||||
bufferLinesRef: React.MutableRefObject<string[]>,
|
||||
setError: (error: string) => void,
|
||||
restartTailing: () => Promise<boolean>
|
||||
) => {
|
||||
return async (reader: ReadableStreamDefaultReader<Uint8Array>) => {
|
||||
let lastDataTime = Date.now();
|
||||
|
||||
const connectionCheckInterval = setInterval(() => {
|
||||
const timeSinceLastData = Date.now() - lastDataTime;
|
||||
if (timeSinceLastData > CONNECTION_TIMEOUT_MS) {
|
||||
clearInterval(connectionCheckInterval);
|
||||
restartTailing();
|
||||
return;
|
||||
}
|
||||
}, CONNECTION_TIMEOUT_MS);
|
||||
|
||||
try {
|
||||
while (true) {
|
||||
const { done, value } = await reader.read();
|
||||
if (done) break;
|
||||
lastDataTime = Date.now();
|
||||
|
||||
const chunk = new TextDecoder().decode(value);
|
||||
const lines = (bufferRef.current + chunk).split("\n");
|
||||
bufferRef.current = lines.pop() || "";
|
||||
bufferLinesRef.current = [...bufferLinesRef.current, ...lines];
|
||||
}
|
||||
} catch (e) {
|
||||
if (e instanceof Error && e.name !== "AbortError") {
|
||||
console.error("Stream processing error:", e);
|
||||
setError(String(e));
|
||||
}
|
||||
} finally {
|
||||
clearInterval(connectionCheckInterval);
|
||||
}
|
||||
};
|
||||
};
|
||||
|
||||
const updateLimitModeTracking = (
|
||||
linesCount: number,
|
||||
attemptsFetchLimitRef: React.MutableRefObject<number>,
|
||||
attemptsFetchLowRef: React.MutableRefObject<number>,
|
||||
isLimitedLogsPerUpdate: boolean,
|
||||
) => {
|
||||
if (linesCount > LOGS_THRESHOLD) {
|
||||
attemptsFetchLimitRef.current++;
|
||||
attemptsFetchLowRef.current = 0;
|
||||
} else {
|
||||
attemptsFetchLowRef.current++;
|
||||
attemptsFetchLimitRef.current = 0;
|
||||
}
|
||||
|
||||
if (attemptsFetchLimitRef.current > MAX_ATTEMPTS_FETCH_LOGS_PER_SECOND) {
|
||||
return true;
|
||||
}
|
||||
|
||||
if (attemptsFetchLowRef.current > MAX_ATTEMPTS_FETCH_LOGS_PER_SECOND) {
|
||||
return false;
|
||||
}
|
||||
|
||||
return isLimitedLogsPerUpdate;
|
||||
};
|
||||
|
||||
const parseLogLines = (lines: string[], counterRef: React.MutableRefObject<bigint>): Logs[] => {
|
||||
return lines
|
||||
.map(line => {
|
||||
try {
|
||||
const parsedLine = line && JSON.parse(line);
|
||||
parsedLine._log_id = counterRef.current++;
|
||||
return parsedLine;
|
||||
} catch (e) {
|
||||
console.error(`Failed to parse "${line}" to JSON\n`, e);
|
||||
return null;
|
||||
}
|
||||
})
|
||||
.filter(Boolean) as Logs[];
|
||||
};
|
||||
|
||||
interface ProcessBufferedLogsParams {
|
||||
lines: string[];
|
||||
limit: number;
|
||||
counterRef: React.MutableRefObject<bigint>;
|
||||
attemptsFetchLimitRef: React.MutableRefObject<number>;
|
||||
attemptsFetchLowRef: React.MutableRefObject<number>;
|
||||
setIsLimitedLogsPerUpdate: (isLimited: boolean) => void;
|
||||
setLogs: React.Dispatch<React.SetStateAction<Logs[]>>;
|
||||
bufferLinesRef: React.MutableRefObject<string[]>;
|
||||
isLimitedLogsPerUpdate: boolean;
|
||||
}
|
||||
|
||||
const processBufferedLogs = ({
|
||||
lines,
|
||||
limit,
|
||||
counterRef,
|
||||
attemptsFetchLimitRef,
|
||||
attemptsFetchLowRef,
|
||||
setIsLimitedLogsPerUpdate,
|
||||
setLogs,
|
||||
bufferLinesRef,
|
||||
isLimitedLogsPerUpdate
|
||||
}: ProcessBufferedLogsParams) => {
|
||||
|
||||
const isLimitLogsMode = updateLimitModeTracking(lines.length, attemptsFetchLimitRef, attemptsFetchLowRef, isLimitedLogsPerUpdate);
|
||||
const limitedLines = isLimitLogsMode && lines.length > LOGS_THRESHOLD ? lines.slice(-LOGS_THRESHOLD) : lines;
|
||||
const newLogs = parseLogLines(limitedLines, counterRef);
|
||||
|
||||
setIsLimitedLogsPerUpdate(isLimitLogsMode);
|
||||
setLogs(prevLogs => {
|
||||
const combinedLogs = [...prevLogs, ...newLogs];
|
||||
return combinedLogs.length > limit ? combinedLogs.slice(-limit) : combinedLogs;
|
||||
});
|
||||
bufferLinesRef.current = [];
|
||||
};
|
||||
|
||||
export const useLiveTailingLogs = (query: string, limit: number) => {
|
||||
const { serverUrl } = useAppState();
|
||||
const [searchParams] = useSearchParams();
|
||||
|
||||
const [logs, setLogs] = useState<Logs[]>([]);
|
||||
const { value: isPaused, setTrue: pauseLiveTailing, setFalse: resumeLiveTailing } = useBoolean(false);
|
||||
const tenant = useTenant();
|
||||
const [error, setError] = useState<ErrorTypes | string>();
|
||||
const [isLimitedLogsPerUpdate, setIsLimitedLogsPerUpdate] = useState(false);
|
||||
|
||||
const counterRef = useRef<bigint>(0n);
|
||||
const abortControllerRef = useRef(new AbortController());
|
||||
const readerRef = useRef<ReadableStreamDefaultReader<Uint8Array> | null>(null);
|
||||
const intervalRef = useRef<ReturnType<typeof setInterval> | null>(null);
|
||||
const bufferRef = useRef<string>("");
|
||||
const bufferLinesRef = useRef<string[]>([]);
|
||||
const attemptsFetchLimitLogsPerSecondCountRef = useRef<number>(0);
|
||||
const attemptsFetchLowLogsPerSecondCountRef = useRef<number>(0);
|
||||
|
||||
const stopLiveTailing = useCallback(() => {
|
||||
if (readerRef.current) {
|
||||
@@ -179,8 +40,13 @@ export const useLiveTailingLogs = (query: string, limit: number) => {
|
||||
const { signal } = abortControllerRef.current;
|
||||
|
||||
setError(undefined);
|
||||
setLogs([]);
|
||||
|
||||
try {
|
||||
const tenant = {
|
||||
AccountID: searchParams.get("accountID") || "0",
|
||||
ProjectID: searchParams.get("projectID") || "0"
|
||||
};
|
||||
const response = await fetch(`${serverUrl}/select/logsql/tail`, {
|
||||
signal,
|
||||
method: "POST",
|
||||
@@ -202,14 +68,25 @@ export const useLiveTailingLogs = (query: string, limit: number) => {
|
||||
const reader = response.body.getReader();
|
||||
readerRef.current = reader;
|
||||
|
||||
const processStream = createStreamProcessor(
|
||||
bufferRef,
|
||||
bufferLinesRef,
|
||||
setError,
|
||||
startLiveTailing
|
||||
);
|
||||
const processStream = async () => {
|
||||
try {
|
||||
while (true) {
|
||||
const { done, value } = await reader.read();
|
||||
if (done) break;
|
||||
|
||||
processStream(reader);
|
||||
// Convert the Uint8Array to a string
|
||||
const chunk = new TextDecoder().decode(value);
|
||||
bufferRef.current += chunk;
|
||||
}
|
||||
} catch (e) {
|
||||
if (e instanceof Error && e.name !== "AbortError") {
|
||||
console.error("Stream processing error:", e);
|
||||
setError(String(e));
|
||||
}
|
||||
}
|
||||
};
|
||||
|
||||
processStream();
|
||||
return true;
|
||||
} catch (e) {
|
||||
if (e instanceof Error && e.name !== "AbortError") {
|
||||
@@ -221,35 +98,42 @@ export const useLiveTailingLogs = (query: string, limit: number) => {
|
||||
}
|
||||
}, [query, stopLiveTailing]);
|
||||
|
||||
|
||||
useEffect(() => {
|
||||
if (isPaused) {
|
||||
const pauseTimerId = setInterval(() => {
|
||||
if (bufferLinesRef.current.length > limit) {
|
||||
bufferLinesRef.current = bufferLinesRef.current.slice(-limit);
|
||||
}
|
||||
}, PROCESSING_INTERVAL_MS);
|
||||
return () => {
|
||||
clearInterval(pauseTimerId);
|
||||
};
|
||||
}
|
||||
if (isPaused) return;
|
||||
|
||||
/**
|
||||
* Process incoming log data at a throttled rate (every 1s)
|
||||
* This interval-based approach prevents CPU overload by:
|
||||
* 1. Batching log processing instead of processing each chunk immediately
|
||||
* 2. Limiting UI updates to a reasonable frequency (1/sec) even when data streams in rapidly
|
||||
* 3. Reducing performance impact when handling large volumes of incoming logs
|
||||
* 4. Allowing efficient garbage collection between processing cycles
|
||||
*/
|
||||
const timerId = setInterval(() => {
|
||||
const lines = bufferLinesRef.current;
|
||||
processBufferedLogs({
|
||||
lines,
|
||||
limit,
|
||||
counterRef,
|
||||
attemptsFetchLimitRef: attemptsFetchLimitLogsPerSecondCountRef,
|
||||
attemptsFetchLowRef: attemptsFetchLowLogsPerSecondCountRef,
|
||||
setIsLimitedLogsPerUpdate,
|
||||
isLimitedLogsPerUpdate,
|
||||
setLogs,
|
||||
bufferLinesRef
|
||||
});
|
||||
}, PROCESSING_INTERVAL_MS);
|
||||
const lines = bufferRef.current.split("\n");
|
||||
bufferRef.current = lines.pop() || "";
|
||||
|
||||
const newLogs = lines
|
||||
.map(line => {
|
||||
try {
|
||||
const parsedLine = line && JSON.parse(line);
|
||||
parsedLine._log_id = counterRef.current++;
|
||||
return parsedLine;
|
||||
} catch (e) {
|
||||
console.error(`Failed to parse "${line}" to JSON\n`, e);
|
||||
return null;
|
||||
}
|
||||
})
|
||||
.filter(Boolean) as Logs[];
|
||||
|
||||
setLogs(prevLogs => {
|
||||
const combinedLogs = [...prevLogs, ...newLogs];
|
||||
return combinedLogs.length > limit ? combinedLogs.slice(-limit) : combinedLogs;
|
||||
});
|
||||
}, 1000);
|
||||
return () => clearInterval(timerId);
|
||||
}, [limit, isPaused, isLimitedLogsPerUpdate]);
|
||||
}, [limit, isPaused]);
|
||||
|
||||
const clearLogs = useCallback(() => {
|
||||
setLogs([]);
|
||||
@@ -263,7 +147,6 @@ export const useLiveTailingLogs = (query: string, limit: number) => {
|
||||
stopLiveTailing,
|
||||
pauseLiveTailing,
|
||||
resumeLiveTailing,
|
||||
clearLogs,
|
||||
isLimitedLogsPerUpdate
|
||||
clearLogs
|
||||
};
|
||||
};
|
||||
};
|
||||
@@ -1,36 +0,0 @@
|
||||
import { describe, expect, it } from "vitest";
|
||||
import { isDecreasing } from "./array";
|
||||
|
||||
describe("isDecreasing", () => {
|
||||
it("should return true for an array with strictly decreasing numbers", () => {
|
||||
expect(isDecreasing([5, 4, 3, 2, 1])).toBe(true);
|
||||
});
|
||||
|
||||
it("should return false for an array with increasing numbers", () => {
|
||||
expect(isDecreasing([1, 2, 3, 4, 5])).toBe(false);
|
||||
});
|
||||
|
||||
it("should return false for an array with equal consecutive numbers", () => {
|
||||
expect(isDecreasing([5, 5, 4, 3, 2])).toBe(false);
|
||||
});
|
||||
|
||||
it("should return false for an empty array", () => {
|
||||
expect(isDecreasing([])).toBe(false);
|
||||
});
|
||||
|
||||
it("should return false for an array with a single element", () => {
|
||||
expect(isDecreasing([1])).toBe(false);
|
||||
});
|
||||
|
||||
it("should return false for an array with both increasing and decreasing numbers", () => {
|
||||
expect(isDecreasing([5, 3, 4, 2, 1])).toBe(false);
|
||||
});
|
||||
|
||||
it("should return true for an array with negative strictly decreasing numbers", () => {
|
||||
expect(isDecreasing([-1, -2, -3, -4])).toBe(true);
|
||||
});
|
||||
|
||||
it("should return false for an array with a mix of positive and negative numbers that do not strictly decrease", () => {
|
||||
expect(isDecreasing([3, 2, -1, -1])).toBe(false);
|
||||
});
|
||||
});
|
||||
@@ -1,4 +1,4 @@
|
||||
export const arrayEquals = (a: (string | number)[], b: (string | number)[]) => {
|
||||
export const arrayEquals = (a: (string|number)[], b: (string|number)[]) => {
|
||||
return a.length === b.length && a.every((val, index) => val === b[index]);
|
||||
};
|
||||
|
||||
@@ -17,8 +17,3 @@ export function groupByMultipleKeys<T>(items: T[], keys: (keyof T)[]): { keys: s
|
||||
}));
|
||||
}
|
||||
|
||||
export const isDecreasing = (arr: number[]): boolean => {
|
||||
if (arr.length < 2) return false;
|
||||
|
||||
return arr.every((v, i) => i === 0 || v < arr[i - 1]);
|
||||
};
|
||||
|
||||
@@ -59,7 +59,7 @@ services:
|
||||
- '--external.alert.source=explore?orgId=1&left=["now-1h","now","VictoriaMetrics",{"expr": },{"mode":"Metrics"},{"ui":[true,true,true,"none"]}]'
|
||||
restart: always
|
||||
vmanomaly:
|
||||
image: victoriametrics/vmanomaly:v1.23.0
|
||||
image: victoriametrics/vmanomaly:v1.21.0
|
||||
depends_on:
|
||||
- "victoriametrics"
|
||||
ports:
|
||||
|
||||
@@ -14,21 +14,6 @@ aliases:
|
||||
---
|
||||
Please find the changelog for VictoriaMetrics Anomaly Detection below.
|
||||
|
||||
## v1.23.0
|
||||
Released: 2025-06-05
|
||||
|
||||
- FEATURE: Added `decay` [argument](https://docs.victoriametrics.com/anomaly-detection/components/models/#decay) to [online models](https://docs.victoriametrics.com/anomaly-detection/components/models/#online-models). This parameters allows for newer data to be weighted more heavily in online models. By default this is set to 1 which means all data points are weighted the same to maintain backward compatibility with existing configs. The closer this value is to 0 the more important new data is.
|
||||
|
||||
- IMPROVEMENT: **Restored back parallelization** in the read/fit/infer pipeline, previously disabled in [v1.22.0](#v1220-experimental) due to deadlock issues. The new implementation prevents deadlocks, allowing to control the parallelization level via `n_workers` in [settings section](https://docs.victoriametrics.com/anomaly-detection/components/settings/). It's suggested to upgrade from [v1.22.0](#v1220) - [v1.22.1](#v1221) to this version to regain the performance benefits of parallel processing.
|
||||
|
||||
- IMPROVEMENT: Added `--dryRun` [argument](https://docs.victoriametrics.com/anomaly-detection/quickstart/#command-line-arguments) to `vmanomaly` to enable dry run mode. This mode allows to validate configuration without executing any actual operations and doesn't require a license. It is particularly useful to test the configurations before deploying them in a production environment.
|
||||
|
||||
- IMPROVEMENT: Enhanced task scheduling to reduce locks between anomaly detection models' fit and inference calls, improving their concurrent performance.
|
||||
|
||||
- IMPROVEMENT: `min_dev_from_expected` model [common argument](https://docs.victoriametrics.com/anomaly-detection/components/models/#minimal-deviation-from-expected) is now bi-directional, allowing you to set *different* thresholds for peaks and drops.
|
||||
|
||||
- BUGFIX: Now `clip_predictions` [model common arg](https://docs.victoriametrics.com/anomaly-detection/components/models/#clip-predictions) is properly used with [online models](https://docs.victoriametrics.com/anomaly-detection/components/models/#online-models), ensuring that the predictions are clipped to the respective query's `data_range` values even if the model saw *less datapoints* than required `min_n_samples_seen_` to produce anomaly scores (e.g., when a new model instance was created during `infer` call for new timeseries not seen at training time).
|
||||
|
||||
## v1.22.1
|
||||
Released: 2025-05-11
|
||||
|
||||
@@ -43,7 +28,7 @@ Released: 2025-04-11
|
||||
|
||||
**(Experimental Patch Release)**
|
||||
|
||||
> Important Notice - this patch disables parallelization to resolve rate but critical deadlock issue that completely halted the fit/infer pipeline (resulting in no anomaly scores, no model refits, and no log output) on multicore systems. Although this change improves resource usage by reducing peak-to-average RAM consumption, it incurs a 2–4x slowdown in fit/infer routines. We recommend upgrading only if your current deployments are experiencing deadlock-related outages. Please upgrade to [v1.23.0](#v1230) or newer for restored parallelization.
|
||||
> Important Notice - this patch disables parallelization to resolve rate but critical deadlock issue that completely halted the fit/infer pipeline (resulting in no anomaly scores, no model refits, and no log output) on multicore systems. Although this change improves resource usage by reducing peak-to-average RAM consumption, it incurs a 2–4x slowdown in fit/infer routines. We recommend upgrading only if your current deployments are experiencing deadlock-related outages. Future releases will reintroduce optimized parallelization.
|
||||
|
||||
- BUGFIX: Resolved an intermittent deadlock in the fit/infer process that previously caused the service to freeze indefinitely, thereby preventing anomaly score production and model refits on multicore systems.
|
||||
|
||||
|
||||
@@ -224,7 +224,7 @@ services:
|
||||
# ...
|
||||
vmanomaly:
|
||||
container_name: vmanomaly
|
||||
image: victoriametrics/vmanomaly:v1.23.0
|
||||
image: victoriametrics/vmanomaly:v1.21.0
|
||||
# ...
|
||||
ports:
|
||||
- "8490:8490"
|
||||
@@ -256,10 +256,9 @@ For Helm chart users, refer to the `persistentVolume` [section](https://github.c
|
||||
|
||||
With the introduction of [online models](https://docs.victoriametrics.com/anomaly-detection/components/models/#online-models) {{% available_from "v1.15.0" anomaly %}} , you can additionally reduce resource consumption (e.g., flatten `fit` stage peaks by querying less data from VictoriaMetrics at once).
|
||||
|
||||
- **Reduced latency**: Online models update incrementally, which can lead to faster response times for anomaly detection since the model continuously adapts to new data without waiting for a batch `fit`.
|
||||
- **Reduced Latency**: Online models update incrementally, which can lead to faster response times for anomaly detection since the model continuously adapts to new data without waiting for a batch `fit`.
|
||||
- **Scalability**: Handling smaller data chunks at a time reduces memory and computational overhead, making it easier to scale the anomaly detection system.
|
||||
- **Optimized resource utilization**: By spreading the computational load over time and reducing peak demands, online models make more efficient use of resources and inducing less data transfer from VictoriaMetrics TSDB, improving overall system performance.
|
||||
- **Faster convergence**: Online models can adapt {{% available_from "v1.23.0" anomaly %}} to changes in data patterns more quickly, which is particularly beneficial in dynamic environments where data characteristics may shift frequently. See `decay` argument descrition [here](https://docs.victoriametrics.com/anomaly-detection/components/models/#decay).
|
||||
- **Improved Resource Utilization**: By spreading the computational load over time and reducing peak demands, online models make more efficient use of system resources, potentially lowering operational costs.
|
||||
|
||||
Here's an example of how we can switch from (offline) [Z-score model](https://docs.victoriametrics.com/anomaly-detection/components/models/#z-score) to [Online Z-score model](https://docs.victoriametrics.com/anomaly-detection/components/models/#online-z-score):
|
||||
|
||||
@@ -293,7 +292,6 @@ models:
|
||||
zscore_example:
|
||||
class: 'zscore_online'
|
||||
min_n_samples_seen: 120 # i.e. minimal relevant seasonality or (initial) fit_window / sampling_frequency
|
||||
decay: 0.999 # decay factor to control how fast the model adapts to new data, the lower, the faster it adapts
|
||||
schedulers: ['periodic']
|
||||
# other model params ...
|
||||
# other config sections ...
|
||||
@@ -432,7 +430,7 @@ options:
|
||||
Here’s an example of using the config splitter to divide configurations based on the `extra_filters` argument from the reader section:
|
||||
|
||||
```sh
|
||||
docker pull victoriametrics/vmanomaly:v1.23.0 && docker image tag victoriametrics/vmanomaly:v1.23.0 vmanomaly
|
||||
docker pull victoriametrics/vmanomaly:v1.21.0 && docker image tag victoriametrics/vmanomaly:v1.21.0 vmanomaly
|
||||
```
|
||||
|
||||
```sh
|
||||
|
||||
@@ -34,26 +34,24 @@ The `vmanomaly` service supports several command-line arguments to configure its
|
||||
> `vmanomaly` support {{% available_from "v1.18.5" anomaly %}} running on config **directories**, see the `config` positional arg description in help message below.
|
||||
|
||||
```shellhelp
|
||||
usage: vmanomaly.py [-h] [--license STRING | --licenseFile PATH] [--license.forceOffline] [--loggerLevel {DEBUG,WARNING,FATAL,ERROR,INFO}] [--watch] [--dryRun] [--outputSpec PATH] config [config ...]
|
||||
usage: vmanomaly.py [-h] [--license STRING | --licenseFile PATH] [--license.forceOffline] [--loggerLevel {INFO,DEBUG,ERROR,WARNING,FATAL}] [--watch] config [config ...]
|
||||
|
||||
VictoriaMetrics Anomaly Detection Service
|
||||
|
||||
positional arguments:
|
||||
config YAML config file(s) or directories containing YAML files. Multiple files will recursively merge each other values so multiple configs can be combined. If a directory is provided,
|
||||
all `.yaml` files inside will be merged, without recursion. Default: vmanomaly.yaml is expected in the current directory.
|
||||
config YAML config file(s) or directories containing YAML files. Multiple files will recursively merge each other values so multiple configs can be combined. If a directory
|
||||
is provided, all `.yaml` files inside will be merged, without recursion. Default: vmanomaly.yaml is expected in the current directory.
|
||||
|
||||
options:
|
||||
-h show this help message and exit
|
||||
--license STRING License key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/trial/ to obtain a trial license.
|
||||
--licenseFile PATH Path to file with license key for VictoriaMetrics Enterprise. See https://victoriametrics.com/products/enterprise/trial/ to obtain a trial license.
|
||||
--license.forceOffline
|
||||
Whether to force offline verification for VictoriaMetrics Enterprise license key, which has been passed either via -license or via -licenseFile command-line flag. The issued
|
||||
license key must support offline verification feature. Contact info@victoriametrics.com if you need offline license verification.
|
||||
--loggerLevel {DEBUG,WARNING,FATAL,ERROR,INFO}
|
||||
Whether to force offline verification for VictoriaMetrics Enterprise license key, which has been passed either via -license or via -licenseFile command-line flag. The
|
||||
issued license key must support offline verification feature. Contact info@victoriametrics.com if you need offline license verification.
|
||||
--loggerLevel {INFO,DEBUG,ERROR,WARNING,FATAL}
|
||||
Minimum level to log. Possible values: DEBUG, INFO, WARNING, ERROR, FATAL.
|
||||
--watch [DEPRECATED SINCE v1.11.0] Watch config files for changes. This option is no longer supported and will be ignored.
|
||||
--dryRun Validate only: parse + merge all YAML(s) and run schema checks, then exit. Does not require a license to run. Does not expose metrics, or launch vmanomaly service(s).
|
||||
--outputSpec PATH Target location of .yaml output spec.
|
||||
```
|
||||
|
||||
You can specify these options when running `vmanomaly` to fine-tune logging levels or handle licensing configurations, as per your requirements.
|
||||
@@ -118,13 +116,13 @@ Below are the steps to get `vmanomaly` up and running inside a Docker container:
|
||||
1. Pull Docker image:
|
||||
|
||||
```sh
|
||||
docker pull victoriametrics/vmanomaly:v1.23.0
|
||||
docker pull victoriametrics/vmanomaly:v1.20.1
|
||||
```
|
||||
|
||||
2. (Optional step) tag the `vmanomaly` Docker image:
|
||||
|
||||
```sh
|
||||
docker image tag victoriametrics/vmanomaly:v1.23.0 vmanomaly
|
||||
docker image tag victoriametrics/vmanomaly:v1.20.1 vmanomaly
|
||||
```
|
||||
|
||||
3. Start the `vmanomaly` Docker container with a *license file*, use the command below.
|
||||
@@ -158,7 +156,7 @@ docker run -it --user 1000:1000 \
|
||||
services:
|
||||
# ...
|
||||
vmanomaly:
|
||||
image: victoriametrics/vmanomaly:v1.23.0
|
||||
image: victoriametrics/vmanomaly:v1.21.0
|
||||
volumes:
|
||||
$YOUR_LICENSE_FILE_PATH:/license
|
||||
$YOUR_CONFIG_FILE_PATH:/config.yml
|
||||
@@ -191,10 +189,9 @@ with [these Helm charts](https://github.com/VictoriaMetrics/helm-charts/blob/mas
|
||||
## How to configure vmanomaly
|
||||
To run `vmanomaly` you need to set up configuration file in `yaml` format.
|
||||
|
||||
> Before deploying, to check the correctness of your configuration validate config file(s) with `--dryRun` [command-line](#command-line-arguments) flag for chosen deployment method (Docker, Kubernetes, etc.). This will parse and merge all YAML files, run schema checks, logs errors and warnings (if found) and then exit without starting the service or requiring a license.
|
||||
|
||||
Here is an example of config file that will run [Facebook Prophet](https://facebook.github.io/prophet/) model, that will be retrained every 2 hours on 14 days of previous data. It will generate [inference metrics](https://docs.victoriametrics.com/anomaly-detection/components/models#vmanomaly-output) (including `anomaly_score`) every 1 minute.
|
||||
|
||||
|
||||
```yaml
|
||||
schedulers:
|
||||
1d_1m:
|
||||
@@ -209,7 +206,7 @@ models:
|
||||
prophet_model:
|
||||
class: 'prophet'
|
||||
provide_series: ['anomaly_score', 'yhat', 'yhat_lower', 'yhat_upper'] # for debugging
|
||||
tz_aware: True # set to True if your data is timezone-aware, to deal with DST changes correctly
|
||||
tz_aware: True
|
||||
tz_use_cyclical_encoding: True
|
||||
tz_seasonalities: # intra-day + intra-week seasonality
|
||||
- name: 'hod' # intra-day seasonality, hour of the day
|
||||
|
||||
@@ -5,7 +5,6 @@ This chapter describes different components, that correspond to respective secti
|
||||
- [Scheduler(s) section](https://docs.victoriametrics.com/anomaly-detection/components/scheduler/) - Required
|
||||
- [Writer section](https://docs.victoriametrics.com/anomaly-detection/components/writer/) - Required
|
||||
- [Monitoring section](https://docs.victoriametrics.com/anomaly-detection/components/monitoring/) - Optional
|
||||
- [Settings section](https://docs.victoriametrics.com/anomaly-detection/components/settings/) - Optional
|
||||
|
||||
> Once the service starts, automated config validation is performed{{% available_from "v1.7.2" anomaly %}}. Please see container logs for errors that need to be fixed to create fully valid config, visiting sections above for examples and documentation.
|
||||
|
||||
@@ -22,10 +21,6 @@ Below, you will find an example illustrating how the components of `vmanomaly` i
|
||||
Here's a minimalistic full config example, demonstrating many-to-many configuration (actual for [latest version](https://docs.victoriametrics.com/anomaly-detection/changelog/)):
|
||||
|
||||
```yaml
|
||||
settings:
|
||||
n_workers: 4 # number of workers to run models in parallel
|
||||
anomaly_score_outside_data_range: 5.0 # default anomaly score for anomalies outside expected data range
|
||||
|
||||
# how and when to run the models is defined by schedulers
|
||||
# https://docs.victoriametrics.com/anomaly-detection/components/scheduler/
|
||||
schedulers:
|
||||
@@ -56,8 +51,7 @@ models:
|
||||
provide_series: ['anomaly_score', 'yhat', 'yhat_lower', 'yhat_upper']
|
||||
queries: ['cpu_seconds_total']
|
||||
schedulers: ['periodic_1w'] # will be attached to 1-week schedule, fit every 1h and infer every 15m
|
||||
min_dev_from_expected: [0.01, 0.01] # minimum deviation from expected value to be even considered as anomaly
|
||||
anomaly_score_outside_data_range: 1.5 # override default anomaly score outside expected data range
|
||||
min_dev_from_expected: 0.01 # if |y - yhat| < 0.01, anomaly score will be 0
|
||||
detection_direction: 'above_expected'
|
||||
args: # model-specific arguments
|
||||
interval_width: 0.98
|
||||
|
||||
@@ -189,11 +189,9 @@ reader:
|
||||
|
||||
### Minimal deviation from expected
|
||||
|
||||
`min_dev_from_expected`{{% available_from "v1.13.0" anomaly %}} argument is designed to **reduce [false positives](https://victoriametrics.com/blog/victoriametrics-anomaly-detection-handbook-chapter-1/#false-positive)** in scenarios where deviations between the actual value (`y`) and the expected value (`yhat`) are **relatively** high. Such deviations can cause models to generate high [anomaly scores](https://docs.victoriametrics.com/anomaly-detection/faq/#what-is-anomaly-score). However, these deviations may not be significant enough in **absolute values** from a business perspective to be considered anomalies. This parameter ensures that anomaly scores for data points where `|y - yhat| < min_dev_from_expected` are explicitly set to 0. By default, if this parameter is not set, it is set to `0` to maintain backward compatibility.
|
||||
`min_dev_from_expected`{{% available_from "v1.13.0" anomaly %}} argument is designed to **reduce [false positives](https://victoriametrics.com/blog/victoriametrics-anomaly-detection-handbook-chapter-1/#false-positive)** in scenarios where deviations between the actual value (`y`) and the expected value (`yhat`) are **relatively** high. Such deviations can cause models to generate high [anomaly scores](https://docs.victoriametrics.com/anomaly-detection/faq/#what-is-anomaly-score). However, these deviations may not be significant enough in **absolute values** from a business perspective to be considered anomalies. This parameter ensures that anomaly scores for data points where `|y - yhat| < min_dev_from_expected` are explicitly set to 0. By default, if this parameter is not set, it behaves as `min_dev_from_expected=0` to maintain backward compatibility.
|
||||
|
||||
> {{% available_from "v1.23.0" anomaly %}} The `min_dev_from_expected` argument can be a list of two float values, allowing separate thresholds for upper and lower deviations. This is useful when the acceptable deviation varies in different directions (e.g., `min_dev_from_expected: [0.01, 0.02]` means that the lower bound is `0.01` when `y` is less than `yhat` and the upper bound is `0.02` when `y` is greater than `yhat`). If only one value is provided, it is broadcasted to both directions, meaning that the same threshold is applied for both upper and lower deviations (e.g., `min_dev_from_expected: 0.01` means that the lower bound is `0.01` when `y` is less than `yhat` and the upper bound is also `0.01` when `y` is greater than `yhat`).
|
||||
|
||||
> `min_dev_from_expected` must be >= 0. The higher the value of `min_dev_from_expected`, the more significant the deviation must be to generate an anomaly score > 1. This helps in filtering out small deviations that may not be meaningful in the context of the monitored metric.
|
||||
> `min_dev_from_expected` must be >= 0. The higher the value of `min_dev_from_expected`, the fewer data points will be available for anomaly detection, and vice versa.
|
||||
|
||||
*Example*: Consider a scenario where CPU utilization is low and oscillates around 0.3% (0.003). A sudden spike to 1.3% (0.013) represents a +333% increase in **relative** terms, but only a +1 percentage point (0.01) increase in **absolute** terms, which may be negligible and not warrant an alert. Setting the `min_dev_from_expected` argument to `0.01` (1%) will ensure that all anomaly scores for deviations <= `0.01` are set to 0.
|
||||
|
||||
@@ -222,13 +220,12 @@ models:
|
||||
zscore_with_min_dev:
|
||||
class: 'zscore' # or 'model.zscore.ZscoreModel' until v1.13.0
|
||||
z_threshold: 3
|
||||
min_dev_from_expected: [5.0, 5.0]
|
||||
min_dev_from_expected: 5.0
|
||||
queries: ['need_to_include_min_dev'] # use such models on queries where domain experience confirm usefulness
|
||||
zscore_wo_min_dev:
|
||||
class: 'zscore' # or 'model.zscore.ZscoreModel' until v1.13.0
|
||||
z_threshold: 3
|
||||
# if not set, equals to setting min_dev_from_expected == 0 (meaning no filtering is applied)
|
||||
# min_dev_from_expected: [0.0, 0.0]
|
||||
# if not set, equals to setting min_dev_from_expected == 0
|
||||
queries: ['normal_behavior'] # use the default where it's not needed
|
||||
```
|
||||
|
||||
@@ -363,7 +360,7 @@ The `anomaly_score_outside_data_range` {{% available_from "v1.20.0" anomaly %}}
|
||||
|
||||
**How it works**
|
||||
- If **not set**, the **default value (`1.01`)** is used for backward compatibility.
|
||||
- If defined at the **service level** (`settings` [section](https://docs.victoriametrics.com/anomaly-detection/components/settings/#anomaly-score-outside-data-range)), it applies to all models **unless overridden at the model level**.
|
||||
- If defined at the **service level** (`settings`), it applies to all models **unless overridden at the model level**.
|
||||
- If set **per model**, it takes **priority over the global setting**.
|
||||
|
||||
**Example (override)**
|
||||
@@ -399,38 +396,6 @@ models:
|
||||
anomaly_score_outside_data_range: 3.0
|
||||
```
|
||||
|
||||
### Decay
|
||||
|
||||
> The `decay` argument works only in combination with [online models](#online-models) like [`ZScoreOnlineModel`](#online-z-score) or [`OnlineQuantileModel`](#online-seasonal-quantile).
|
||||
|
||||
The `decay` {{% available_from "v1.23.0" anomaly %}} argument is used to control the (exponential) **decay factor** for online models, which determines how quickly the model adapts to new data. It is a float value between `0.0` and `1.0`, where:
|
||||
- `1.0` means no decay (the model treats all data equally, without giving more weight to recent data). This is the default value for backward compatibility.
|
||||
- Less than `1.0` means that the model will give more weight to recent data, effectively "forgetting" older data over time.
|
||||
|
||||
Roughly speaking, for the recent N datapoints model processes `decay` = `d` means that these datapoints will contribute to the model as [1 - d^X] percent of total importance, for example decay of
|
||||
- `0.99` means that 100 recent datapoints will contribute as [1 - 0.99^100] = 63.23% of total importance
|
||||
- `0.999` means that 1000 recent datapoints will contribute as [1 - 0.999^1000] = 63.23% of total importance
|
||||
|
||||
For example, if the model is updated every 5 minutes (`scheduler.infer_every`), on five 1-minute datapoints and there is a need to keep the last 1 day of data as the most impactful, setting `decay: 0.996` will ensure that the model has the last (86400/60) = 1440 datapoints contributing as [1 - 0.996^1440] = 99.6% of total importance, without the need to re-train the model on all 1440 datapoints every day with `fit_every: 1d` (which would be the limitation for [offline models](#offline-models)).
|
||||
|
||||
Example config:
|
||||
|
||||
```yaml
|
||||
# other components like writer, schedulers, monitoring ...
|
||||
reader:
|
||||
# ...
|
||||
queries:
|
||||
q1: metricsql_expression1
|
||||
# ...
|
||||
|
||||
models:
|
||||
online_zscore:
|
||||
class: 'zscore_online'
|
||||
z_threshold: 3.0
|
||||
decay: 0.996 # decay factor for online model, default is 1.0
|
||||
queries: ['q1']
|
||||
```
|
||||
|
||||
|
||||
## Model types
|
||||
|
||||
@@ -661,7 +626,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -691,7 +656,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -738,7 +703,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -774,7 +739,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -830,7 +795,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -866,7 +831,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -906,7 +871,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -942,7 +907,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -997,7 +962,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -1034,7 +999,7 @@ models:
|
||||
# schedulers: [all scheduler aliases defined in `scheduler` section]
|
||||
# queries: [all query aliases defined in `reader.queries` section]
|
||||
# detection_direction: 'both' # meaning both drops and spikes will be captured
|
||||
# min_dev_from_expected: [0.0, 0.0] # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# min_dev_from_expected: 0.0 # meaning, no minimal threshold is applied to prevent smaller anomalies
|
||||
# scale: [1.0, 1.0] # if needed, prediction intervals' width can be increased (>1) or narrowed (<1)
|
||||
# clip_predictions: False # if data_range for respective `queries` is set in reader, `yhat.*` columns will be clipped
|
||||
# anomaly_score_outside_data_range: 1.01 # auto anomaly score (1.01) if `y` (real value) is outside of data_range, if set
|
||||
@@ -1276,7 +1241,7 @@ monitoring:
|
||||
Let's pull the docker image for `vmanomaly`:
|
||||
|
||||
```sh
|
||||
docker pull victoriametrics/vmanomaly:v1.23.0
|
||||
docker pull victoriametrics/vmanomaly:v1.21.0
|
||||
```
|
||||
|
||||
Now we can run the docker container putting as volumes both config and model file:
|
||||
@@ -1290,7 +1255,7 @@ docker run -it \
|
||||
-v $(PWD)/license:/license \
|
||||
-v $(PWD)/custom_model.py:/vmanomaly/model/custom.py \
|
||||
-v $(PWD)/custom.yaml:/config.yaml \
|
||||
victoriametrics/vmanomaly:v1.23.0 /config.yaml \
|
||||
victoriametrics/vmanomaly:v1.21.0 /config.yaml \
|
||||
--licenseFile=/license
|
||||
```
|
||||
|
||||
|
||||
@@ -65,10 +65,8 @@ There is change{{% available_from "v1.13.0" anomaly %}} of [`queries`](https://d
|
||||
> Having **different** individual `step` args for queries (i.e. `30s` for `q1` and `2m` for `q2`) is not yet supported for [multivariate model](https://docs.victoriametrics.com/anomaly-detection/components/models/#multivariate-models) if you want to run it on several queries simultaneously (i.e. setting [`queries`](https://docs.victoriametrics.com/anomaly-detection/components/models/#queries) arg of a model to [`q1`, `q2`]).
|
||||
|
||||
- `data_range`{{% available_from "v1.15.1" anomaly %}} (list[float | string]): It allows defining **valid** data ranges for input per individual query in `queries`, resulting in:
|
||||
- **High anomaly scores** (>1) when the *data falls outside the expected range*, indicating a data range constraint violation (e.g. improperly configured metricsQL query, sensor malfunction, overflows in underlying metrics, etc.). Anomaly scores can be set to a specific value, like `5`, to indicate a strong violation, using the `anomaly_score_outside_data_range` [arg](https://docs.victoriametrics.com/anomaly-detection/components/models/#score-outside-data-range) of a respective model this query is used in.
|
||||
- **Lowest anomaly scores** (=0) when the *model's predictions (`yhat`) fall outside the expected range*, meaning uncertain predictions that does not really aligh with the data.
|
||||
|
||||
Works together with `anomaly_score_outside_data_range` [arg](https://docs.victoriametrics.com/anomaly-detection/components/models/#score-outside-data-range) of a model to determine the anomaly score for such cases as well as with `clip_predictions` [arg](https://docs.victoriametrics.com/anomaly-detection/components/models/#clip-predictions) of a model to clip the predictions to the expected range.
|
||||
- **High anomaly scores** (>1) when the *data falls outside the expected range*, indicating a data constraint violation.
|
||||
- **Lowest anomaly scores** (=0) when the *model's predictions (`yhat`) fall outside the expected range*, meaning uncertain predictions.
|
||||
|
||||
> If not set explicitly (or if older config style prior to [v1.13.0](https://docs.victoriametrics.com/anomaly-detection/changelog/#v1130)) is used, then it is set to reader-level `data_range` arg{{% available_from "v1.18.1" anomaly %}}
|
||||
|
||||
|
||||
@@ -1,139 +0,0 @@
|
||||
---
|
||||
title: Settings
|
||||
weight: 6
|
||||
menu:
|
||||
docs:
|
||||
parent: "vmanomaly-components"
|
||||
weight: 6
|
||||
identifier: "vmanomaly-settings"
|
||||
tags:
|
||||
- metrics
|
||||
- enterprise
|
||||
aliases:
|
||||
- ./settings.html
|
||||
---
|
||||
|
||||
Through the **Settings** section of a config, you can configure the following parameters of the anomaly detection service:
|
||||
|
||||
## Anomaly Score Outside Data Range
|
||||
|
||||
This argument allows you to override the anomaly score for anomalies that are caused by values outside the expected **data range** of particular [query](https://docs.victoriametrics.com/anomaly-detection/components/models#queries). The reasons for such anomalies can be various, such as improperly constructed metricsQL queries, sensor malfunctions, or other issues that lead to unexpected values in the data and reqire investigation.
|
||||
|
||||
> If not set, the [anomaly score](https://docs.victoriametrics.com/anomaly-detection/faq#what-is-anomaly-score) for such anomalies defaults to `1.01` for backward compatibility, however, it is recommended to set it to a higher value, such as `5.0`, to better reflect the severity of anomalies that fall outside the expected data range to catch them faster and check the query for correctness and underlying data for potential issues.
|
||||
|
||||
Here's an example configuration that sets default anomaly score outside expected data range to `5.0` and overrides it for a specific model to `1.5`:
|
||||
|
||||
```yaml
|
||||
settings:
|
||||
n_workers: 4
|
||||
anomaly_score_outside_data_range: 5.0
|
||||
|
||||
schedulers:
|
||||
periodic:
|
||||
class: periodic
|
||||
fit_every: 5m
|
||||
fit_window: 3h
|
||||
infer_every: 30s
|
||||
# other schedulers
|
||||
|
||||
models:
|
||||
zscore_online_override:
|
||||
class: zscore_online
|
||||
z_threshold: 3.5
|
||||
clip_predictions: True
|
||||
# will be inherited from settings.anomaly_score_outside_data_range
|
||||
# anomaly_score_outside_data_range: 5.0
|
||||
zscore_online_override:
|
||||
class: zscore_online
|
||||
z_threshold: 3.5
|
||||
clip_predictions: True
|
||||
anomaly_score_outside_data_range: 1.5 # will override settings.anomaly_score_outside_data_range
|
||||
# other models
|
||||
|
||||
reader:
|
||||
class: vm
|
||||
datasource_url: 'https://play.victoriametrics.com'
|
||||
tenant_id: "0"
|
||||
queries:
|
||||
error_rate:
|
||||
expr: 'rand()*100 + rand()' # example query that generates values between 1 and 100 and sometimes exceeds 100
|
||||
data_range: [0., 100.] # expected data range for the underlying query and business logic
|
||||
# other queries
|
||||
sampling_period: 30s
|
||||
latency_offset: 10ms
|
||||
query_from_last_seen_timestamp: False
|
||||
verify_tls: False
|
||||
# other reader settings
|
||||
|
||||
writer:
|
||||
class: "vm"
|
||||
datasource_url: http://localhost:8428
|
||||
metric_format:
|
||||
__name__: "$VAR"
|
||||
for: "$QUERY_KEY"
|
||||
# other writer settings
|
||||
|
||||
monitoring:
|
||||
push:
|
||||
url: http://localhost:8428
|
||||
push_frequency: 1m
|
||||
# other monitoring settings
|
||||
```
|
||||
|
||||
## Parallelization
|
||||
|
||||
The `n_workers` argument allows you to explicitly specify the number of workers for internal parallelization of the service. This can help improve performance on multicore systems by allowing the service to process multiple tasks in parallel. For backward compatibility, it's set to `1` by default, meaning that the service will run in a single-threaded mode. It should be an integer greater than or equal to `-1`, where `-1` and `0` means that the service will automatically inherit the number of workers based on the number of available CPU cores.
|
||||
|
||||
Increasing the number can be particularly useful when dealing with a high volume of queries returning many (long) timeseries.
|
||||
Decreasing the number can be useful when running the service on a system with limited resources or when you want to reduce the load on the system.
|
||||
|
||||
Here's an example configuration that uses 4 workers for service's internal parallelization:
|
||||
|
||||
```yaml
|
||||
settings:
|
||||
n_workers: 4
|
||||
|
||||
schedulers:
|
||||
periodic:
|
||||
class: periodic
|
||||
fit_every: 5m
|
||||
fit_window: 3h
|
||||
infer_every: 30s
|
||||
# other schedulers
|
||||
|
||||
models:
|
||||
zscore_online_override:
|
||||
class: zscore_online
|
||||
z_threshold: 3.5
|
||||
clip_predictions: True
|
||||
# other models
|
||||
|
||||
reader:
|
||||
class: vm
|
||||
datasource_url: 'https://play.victoriametrics.com'
|
||||
tenant_id: "0"
|
||||
queries:
|
||||
example_query:
|
||||
expr: 'rand() + 1' # example query that generates random values between 1 and 2
|
||||
data_range: [1., 2.]
|
||||
# other queries
|
||||
sampling_period: 30s
|
||||
latency_offset: 10ms
|
||||
query_from_last_seen_timestamp: False
|
||||
verify_tls: False
|
||||
# other reader settings
|
||||
|
||||
writer:
|
||||
class: "vm"
|
||||
datasource_url: http://localhost:8428
|
||||
metric_format:
|
||||
__name__: "$VAR"
|
||||
for: "$QUERY_KEY"
|
||||
# other writer settings
|
||||
|
||||
monitoring:
|
||||
push:
|
||||
url: http://localhost:8428
|
||||
push_frequency: 1m
|
||||
# other monitoring settings
|
||||
```
|
||||
@@ -387,7 +387,7 @@ services:
|
||||
restart: always
|
||||
vmanomaly:
|
||||
container_name: vmanomaly
|
||||
image: victoriametrics/vmanomaly:v1.23.0
|
||||
image: victoriametrics/vmanomaly:v1.21.0
|
||||
depends_on:
|
||||
- "victoriametrics"
|
||||
ports:
|
||||
|
||||
@@ -40,8 +40,6 @@ according to [these docs](https://docs.victoriametrics.com/victorialogs/quicksta
|
||||
* FEATURE: [`uniq_values` stats function](https://docs.victoriametrics.com/victorialogs/logsql/#uniq_values-stats): allow fetching unique values for all the fields with common prefix via `uniq_values(prefix*)` syntax.
|
||||
* FEATURE: [`values` stats function](https://docs.victoriametrics.com/victorialogs/logsql/#values-stats): allow fetching values for all the fields with common prefix via `values(prefix*)` syntax.
|
||||
* FEATURE: [`json_values` stats function](https://docs.victoriametrics.com/victorialogs/logsql/#json_values-stats): allow fetching values for all the fields with common prefix via `json_values(prefix*)` syntax.
|
||||
* FEATURE: [`-insert.maxLineSizeBytes`](https://docs.victoriametrics.com/victorialogs/faq/#what-length-a-log-record-is-expected-to-have): add logging of the number of bytes skipped for oversize lines.
|
||||
* FEATURE: add `-insert.disable` and `-select.disable` command-line flags for disabling both public and internal HTTP endpoints (`/insert/*` + `/internal/insert` and `/select/*` + `/internal/select/*` respectively). See [#9061](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9061).
|
||||
|
||||
* BUGFIX: [query API](https://docs.victoriametrics.com/victorialogs/querying/#querying-logs): properly set storage node authorization in cluster mode when [Basic Auth](https://docs.victoriametrics.com/victorialogs/cluster/#security) is enabled. See [#9080](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9080).
|
||||
|
||||
|
||||
@@ -4189,7 +4189,7 @@ Internally duration values are converted into nanoseconds.
|
||||
- It is highly recommended specifying [stream filter](#stream-filter) in order to narrow down the search
|
||||
to specific [log streams](https://docs.victoriametrics.com/victorialogs/keyconcepts/#stream-fields).
|
||||
- It is recommended specifying [log fields](https://docs.victoriametrics.com/victorialogs/keyconcepts/#data-model) you need in query results
|
||||
with the [`fields` pipe](#fields-pipe), if the selected log entries contain big number of fields, which aren't interesting to you.
|
||||
with the [`field` pipe](#fields-pipe), if the selected log entries contain big number of fields, which aren't interesting to you.
|
||||
This saves disk read IO and CPU time needed for reading and unpacking all the log fields from disk.
|
||||
- Move faster filters such as [word filter](#word-filter) and [phrase filter](#phrase-filter) to the beginning of the query.
|
||||
This rule doesn't apply to [time filter](#time-filter) and [stream filter](#stream-filter), which can be put at any place of the query.
|
||||
|
||||
@@ -398,8 +398,6 @@ Pass `-help` to VictoriaLogs in order to see the list of supported command-line
|
||||
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), y (year). If suffix isn't set, then the duration is counted in months (default 2d)
|
||||
-http.connTimeout duration
|
||||
Incoming connections to -httpListenAddr are closed after the configured timeout. This may help evenly spreading load among a cluster of services behind TCP-level load balancer. Zero value disables closing of incoming connections (default 2m0s)
|
||||
-http.disableCORS
|
||||
Disable CORS for all origins (*)
|
||||
-http.disableResponseCompression
|
||||
Disable compression of HTTP responses to save CPU resources. By default, compression is enabled to save network bandwidth
|
||||
-http.header.csp string
|
||||
@@ -433,8 +431,6 @@ Pass `-help` to VictoriaLogs in order to see the list of supported command-line
|
||||
The interval for guaranteed saving of in-memory data to disk. The saved data survives unclean shutdowns such as OOM crash, hardware reset, SIGKILL, etc. Bigger intervals may help increase the lifetime of flash storage with limited write cycles (e.g. Raspberry PI). Smaller intervals increase disk IO load. Minimum supported value is 1s (default 5s)
|
||||
-insert.concurrency int
|
||||
The average number of concurrent data ingestion requests, which can be sent to every -storageNode (default 2)
|
||||
-insert.disable
|
||||
Whether to disable /insert/* HTTP endpoints
|
||||
-insert.disableCompression
|
||||
Whether to disable compression when sending the ingested data to -storageNode nodes. Disabled compression reduces CPU usage at the cost of higher network usage
|
||||
-insert.maxFieldsPerLine int
|
||||
@@ -502,7 +498,7 @@ Pass `-help` to VictoriaLogs in order to see the list of supported command-line
|
||||
The maximum size in bytes of a single Loki request
|
||||
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 67108864)
|
||||
-maxConcurrentInserts int
|
||||
The maximum number of concurrent insert requests. Set higher value when clients send data over slow networks. Default value depends on the number of available CPU cores. It should work fine in most cases since it minimizes resource usage. See also -insert.maxQueueDuration (default 28)
|
||||
The maximum number of concurrent insert requests. Set higher value when clients send data over slow networks. Default value depends on the number of available CPU cores. It should work fine in most cases since it minimizes resource usage. See also -insert.maxQueueDuration
|
||||
-memory.allowedBytes size
|
||||
Allowed size of system memory VictoriaMetrics caches may occupy. This option overrides -memory.allowedPercent if set to a non-zero value. Too low a value may increase the cache miss rate usually resulting in higher CPU and disk IO usage. Too high a value may evict too much data from the OS page cache resulting in higher disk IO usage
|
||||
Supports the following optional suffixes for size values: KB, MB, GB, TB, KiB, MiB, GiB, TiB (default 0)
|
||||
@@ -550,13 +546,11 @@ Pass `-help` to VictoriaLogs in order to see the list of supported command-line
|
||||
Log entries with timestamps older than now-retentionPeriod are automatically deleted; log entries with timestamps outside the retention are also rejected during data ingestion; the minimum supported retention is 1d (one day); see https://docs.victoriametrics.com/victorialogs/#retention ; see also -retention.maxDiskSpaceUsageBytes
|
||||
The following optional suffixes are supported: s (second), h (hour), d (day), w (week), y (year). If suffix isn't set, then the duration is counted in months (default 7d)
|
||||
-search.maxConcurrentRequests int
|
||||
The maximum number of concurrent search requests. It shouldn't be high, since a single request can saturate all the CPU cores, while many concurrently executed requests may require high amounts of memory. See also -search.maxQueueDuration (default 14)
|
||||
The maximum number of concurrent search requests. It shouldn't be high, since a single request can saturate all the CPU cores, while many concurrently executed requests may require high amounts of memory. See also -search.maxQueueDuration
|
||||
-search.maxQueryDuration duration
|
||||
The maximum duration for query execution. It can be overridden to a smaller value on a per-query basis via 'timeout' query arg (default 30s)
|
||||
-search.maxQueueDuration duration
|
||||
The maximum time the search request waits for execution when -search.maxConcurrentRequests limit is reached; see also -search.maxQueryDuration (default 10s)
|
||||
-select.disable
|
||||
Whether to disable /select/* HTTP endpoints
|
||||
-select.disableCompression
|
||||
Whether to disable compression for select query responses received from -storageNode nodes. Disabled compression reduces CPU usage at the cost of higher network usage
|
||||
-storage.minFreeDiskSpaceBytes size
|
||||
@@ -620,14 +614,6 @@ Pass `-help` to VictoriaLogs in order to see the list of supported command-line
|
||||
Compression method for syslog messages received at the corresponding -syslog.listenAddr.udp. Supported values: none, gzip, deflate. See https://docs.victoriametrics.com/victorialogs/data-ingestion/syslog/#compression
|
||||
Supports an array of values separated by comma or specified via multiple flags.
|
||||
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
|
||||
-syslog.decolorizeFields.tcp array
|
||||
Fields to remove ANSI color codes across logs ingested via the corresponding -syslog.listenAddr.tcp. See https://docs.victoriametrics.com/victorialogs/data-ingestion/syslog/#decolorizing-fields
|
||||
Supports an array of values separated by comma or specified via multiple flags.
|
||||
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
|
||||
-syslog.decolorizeFields.udp array
|
||||
Fields to remove ANSI color codes across logs ingested via the corresponding -syslog.listenAddr.udp. See https://docs.victoriametrics.com/victorialogs/data-ingestion/syslog/#decolorizing-fields
|
||||
Supports an array of values separated by comma or specified via multiple flags.
|
||||
Value can contain comma inside single-quoted or double-quoted string, {}, [] and () braces.
|
||||
-syslog.extraFields.tcp array
|
||||
Fields to add to logs ingested via the corresponding -syslog.listenAddr.tcp. See https://docs.victoriametrics.com/victorialogs/data-ingestion/syslog/#adding-extra-fields
|
||||
Supports an array of values separated by comma or specified via multiple flags.
|
||||
|
||||
@@ -130,17 +130,6 @@ It is also recommended authorizing HTTPS requests to `vlstorage` via Basic Auth:
|
||||
Another option is to use third-party HTTP proxies such as [vmauth](https://docs.victoriametrics.com/victoriametrics/vmauth/), `nginx`, etc. for authorizing and encrypting communications
|
||||
between VictoriaLogs cluster components over untrusted networks.
|
||||
|
||||
By default, all the logs component (vlinsert, vlselect, vlstorage) support all the HTTP endpoints including `/insert/*` and `/select/*`. It's recommended to disable select endpoints on `vlinsert` and insert endpoints on `vlselect`:
|
||||
|
||||
```sh
|
||||
# Disable select endpoints on vlinsert
|
||||
./victoria-logs-prod -storageNode=... -select.disable
|
||||
|
||||
# Disable insert endpoints on vlselect
|
||||
./victoria-logs-prod -storageNode=... -insert.disable
|
||||
```
|
||||
|
||||
This helps prevent sending select requests to `vlinsert` nodes or insert requests to `vlselect` nodes in case of misconfiguration in the authorization proxy in front of the `vlinsert` and `vlselect` nodes.
|
||||
|
||||
## Quick start
|
||||
|
||||
|
||||
@@ -46,7 +46,7 @@ See [the list of supported Journald fields](https://www.freedesktop.org/software
|
||||
## Multitenancy
|
||||
|
||||
By default VictoriaLogs stores logs ingested via journald protocol into `(AccountID=0, ProjectID=0)` [tenant](https://docs.victoriametrics.com/victorialogs/#multitenancy).
|
||||
This can be changed by passing the needed tenant in the format `AccountID:ProjectID` at the `-journald.tenantID` command-line flag.
|
||||
This can be changed by passing the needed tenant in the format `AccountID:ProjectID` at the `-journlad.tenantID` command-line flag.
|
||||
For example, `-journald.tenantID=123:456` would store logs ingested via journald protocol into `(AccountID=123, ProjectID=456)` tenant.
|
||||
|
||||
See also:
|
||||
|
||||
@@ -3,7 +3,7 @@ title: Deployments
|
||||
weight: 0
|
||||
menu:
|
||||
docs:
|
||||
weight: 3
|
||||
weight: 5
|
||||
parent: cloud
|
||||
identifier: deployments
|
||||
pageRef: /victoriametrics-cloud/deployments/
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 49 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 58 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 46 KiB |
@@ -1,120 +0,0 @@
|
||||
---
|
||||
weight: 10
|
||||
title: Exploring Data
|
||||
menu:
|
||||
docs:
|
||||
parent: "cloud"
|
||||
weight: 4
|
||||
name: Exploring Data
|
||||
tags:
|
||||
- metrics
|
||||
- cloud
|
||||
- enterprise
|
||||
---
|
||||
|
||||
VictoriaMetrics Cloud helps users to analyze time series data and troubleshoot
|
||||
queries through the built-in `Explore` utility, powered by [VMUI](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#vmui).
|
||||
This functionality is directly accessible in the two following ways:
|
||||
1. Explore page at [console.victoriametrics.cloud/explore](https://console.victoriametrics.cloud/explore),
|
||||
1. Per deployment, via a dedicated URL pattern: `console.victoriametrics.cloud/deployment/<DEPLOYMENT_ID>/explore`
|
||||
|
||||
## What is VMUI?
|
||||
|
||||
Full VMUI documentation may be found [here](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#vmui),
|
||||
which is maintained and updated alongside product releases.
|
||||
|
||||
[VMUI](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#vmui) is the
|
||||
native user interface for VictoriaMetrics, designed to help users explore, troubleshoot, and optimize
|
||||
their queries and metrics. In VictoriaMetrics Cloud, this UI is integrated into the **Explore** view,
|
||||
offering an accessible toolset to [get instant value from data](https://docs.victoriametrics.com/victoriametrics-cloud/get-started/features/#get-instant-value-from-your-data).
|
||||
|
||||
### Playground
|
||||
The best way to understand VMUI is by directly interacting with it. If you are curious, the available
|
||||
[playground](https://play.victoriametrics.com/) allows you to check a real example of a VictoriaMetrics
|
||||
Cluster installation. It is available for testing the query engine, relabeling debugger, other tools
|
||||
and pages provided by VMUI.
|
||||
|
||||
### Visual Query Exploration
|
||||
|
||||
The `Query` utility in the Explore page allows you to easily:
|
||||
* Visualize your own data in graphs, table or json formats
|
||||
* Combine several queries at the same time
|
||||
* Prettify your queries to improve readability
|
||||
* Autocomplete to help you writing queries
|
||||
* Trace your queries to understand behavior
|
||||
|
||||
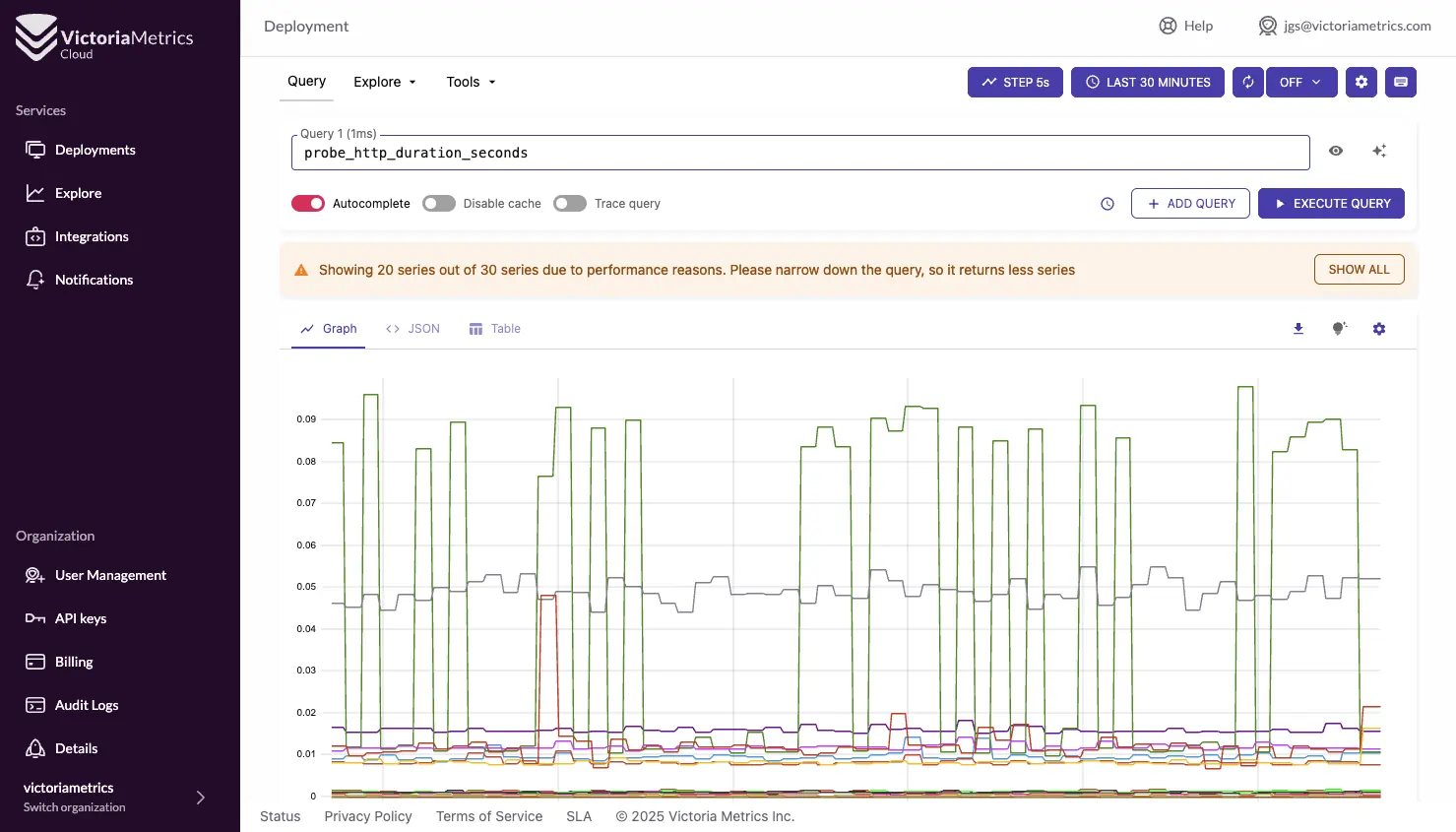
|
||||
<figcaption style="text-align: center; font-style: italic;">Visual Query Exploration in VictoriaMetrics Cloud</figcaption>
|
||||
|
||||
### Exploring metrics
|
||||
|
||||
VMUI provides built-in tools to analyze the structure and volume of your metrics data:
|
||||
|
||||
- **Explore Prometheus Metrics** helps you browse available metrics by job and instance, allowing to build simple charts by just selecting metric names.
|
||||
- **Explore Cardinality** offers insight into the complexity of your time series data, including label dimensions, high-cardinality metrics, and label usage statistics. This is especially useful for optimizing storage and query performance.
|
||||
- **Top Queries** By tracking the last 20,000 queries with durations of at least 1ms, it shows the most frequently executed queries, those with the highest average execution time, and those with the longest cumulative execution time.
|
||||
- **Active Queries** lists currently running queries along with execution duration, time range, and the client that initiated them.
|
||||
|
||||
> [!IMPORTANT] These tools can help you to understand your observability footprint
|
||||
> For example, preventing issues related to excessive cardinality, or debugging performance bottlenecks to identify inefficient queries in real time.
|
||||
|
||||
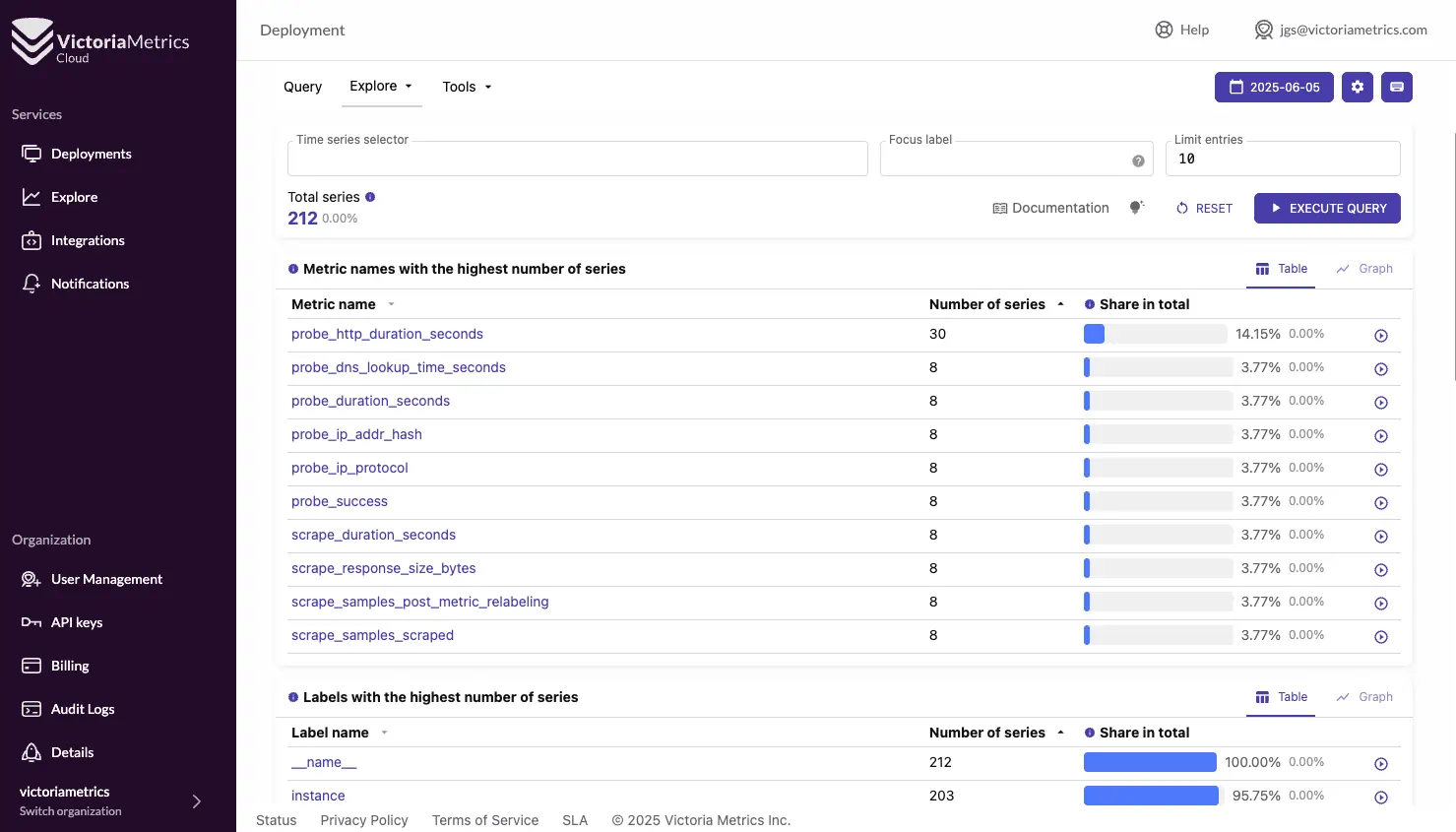
|
||||
<figcaption style="text-align: center; font-style: italic;">Metrics and Cardinality Explorer</figcaption>
|
||||
|
||||
### Debugging and Analysis Utilities
|
||||
|
||||
VMUI offers the following utilities for in-depth debugging:
|
||||
|
||||
- **Raw Query** lets you inspect raw time series samples, aiding in the diagnosis of unexpected results.
|
||||
- **Query and Trace Analyzers** allow you to export and later re-load queries and execution traces for offline inspection.
|
||||
- Tools like the **WITH expressions playground**, **metric relabel debugger**, **downsampling debugger**, and **retention filters debugger** help validate complex configuration logic and query constructs interactively.
|
||||
|
||||
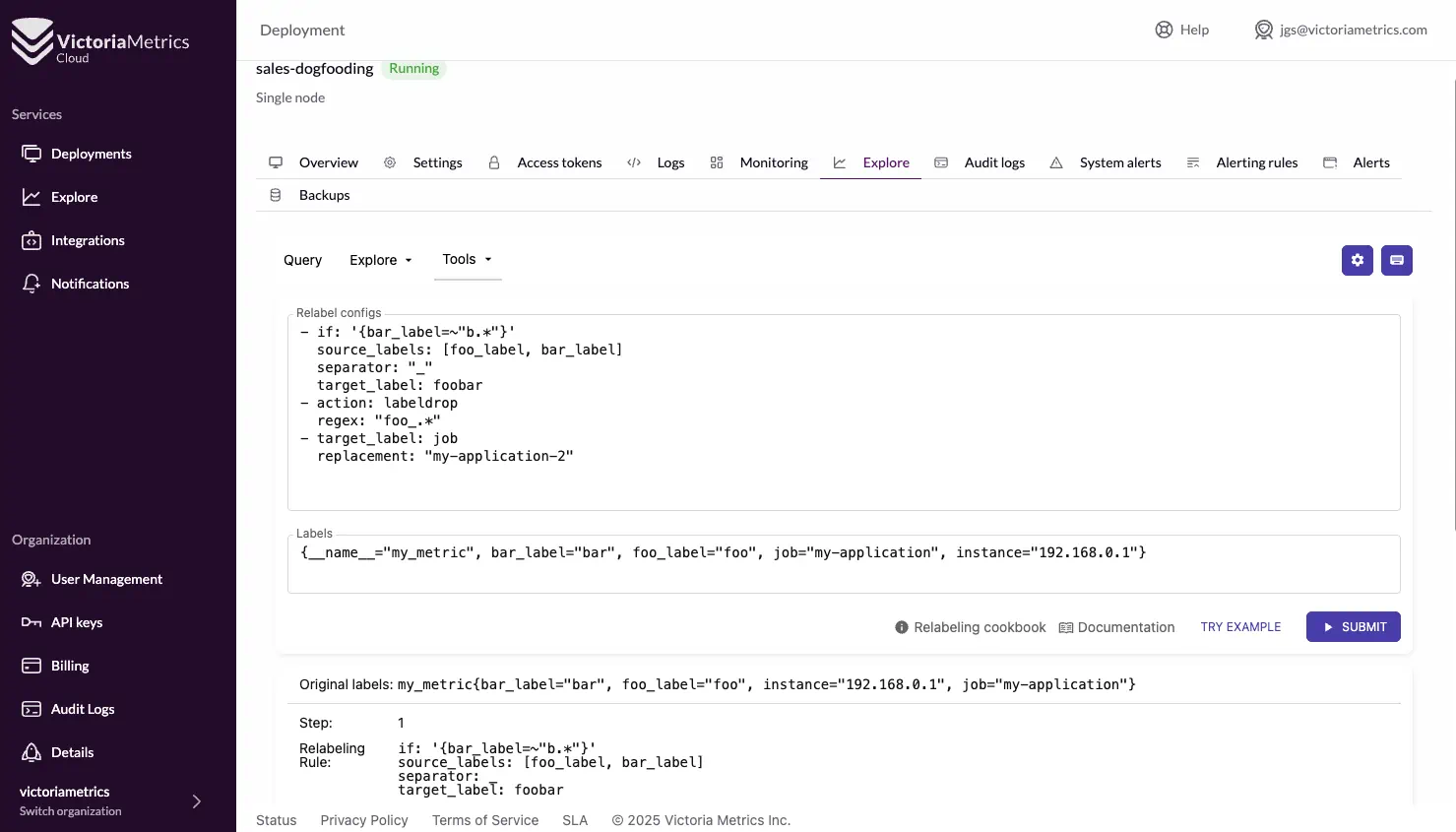
|
||||
<figcaption style="text-align: center; font-style: italic;">Explore tools: Relabel configs</figcaption>
|
||||
|
||||
> [!TIP] Stay up to date!
|
||||
> For the full and always-up-to-date list of features, please refer to the [official VMUI documentation](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#vmui).
|
||||
|
||||
|
||||
## MetricsQL
|
||||
In addition, VictoriaMetrics Cloud supports advanced querying through [MetricsQL](https://docs.victoriametrics.com/victoriametrics/metricsql/),
|
||||
a powerful PromQL-compatible language that offers enhancements tailored for high-performance
|
||||
environments. MetricsQL is fully supported in the Explore UI and can also be used in
|
||||
[Grafana dashboards](https://docs.victoriametrics.com/grafana/#step-3-configure-the-data-source)
|
||||
for long-term observability workflows.
|
||||
|
||||
### What is MetricsQL?
|
||||
|
||||
[MetricsQL](https://docs.victoriametrics.com/victoriametrics/metricsql/) is VictoriaMetrics' powerful query language, designed as a high-performance, backwards-compatible extension of PromQL (Prometheus Query Language). It retains full compatibility with PromQL syntax while introducing enhancements that make it better suited for large-scale environments and advanced analytics.
|
||||
|
||||
### Using MetricsQL in VictoriaMetrics Cloud
|
||||
|
||||
MetricsQL is natively supported in the **Explore** section of VictoriaMetrics Cloud, where you can write, run, and visualize queries in real time. The interface includes autocomplete for MetricsQL syntax, functions, and label selectors—streamlining query creation and reducing the chance of errors.
|
||||
|
||||
You can also use MetricsQL in [Grafana](https://docs.victoriametrics.com/grafana/#step-3-configure-the-data-source)
|
||||
dashboards by configuring the [VictoriaMetrics data source](https://grafana.com/grafana/plugins/victoriametrics-metrics-datasource/),
|
||||
enabling consistent query logic across operational and visualization layers.
|
||||
|
||||
For deeper usage examples and advanced query patterns, please refer to the [official MetricsQL documentation](https://docs.victoriametrics.com/victoriametrics/metricsql/).
|
||||
|
||||
### Key Functionality in MetricsQL
|
||||
|
||||
MetricsQL extends PromQL with several unique capabilities:
|
||||
|
||||
- **`WITH` expressions**: Define temporary named subqueries to improve readability and reuse logic across queries.
|
||||
- **Performance-tuned functions**: Functions like `avg_over_time`, `count_over_time`, and others are optimized for efficient computation over long durations.
|
||||
- **Flexible filtering**: Enhanced match operators (`=~`, `!~`, `=`, `!=`) and aggregation logic make it easier to craft precise queries.
|
||||
- **Downsampling and rate smoothing**: Built-in functions help reduce noise and CPU cost for long-range queries.
|
||||
|
||||
For a full list of functions and capabilities, see the [MetricsQL reference](https://docs.victoriametrics.com/victoriametrics/metricsql/).
|
||||
|
||||
### Why Use MetricsQL?
|
||||
|
||||
MetricsQL addresses many real-world limitations found in PromQL when working with high-cardinality
|
||||
time series data, large datasets, or complex calculations. It introduces performance optimizations
|
||||
and new functions that enable more flexible, efficient, and maintainable queries. Users benefit from:
|
||||
|
||||
- **Better performance** on large-scale queries
|
||||
- **Enhanced expressiveness** with additional functions and operators
|
||||
- **Improved readability** through support for `WITH` expressions (query macros)
|
||||
- **Lower cost** by optimizing query execution paths
|
||||
@@ -537,7 +537,8 @@ By default, the following TCP ports are used:
|
||||
|
||||
It is recommended setting up [vmagent](https://docs.victoriametrics.com/victoriametrics/vmagent/)
|
||||
or Prometheus to scrape `/metrics` pages from all the cluster components, so they can be monitored and analyzed
|
||||
with [the official Grafana dashboard for VictoriaMetrics cluster](https://grafana.com/grafana/dashboards/11176).
|
||||
with [the official Grafana dashboard for VictoriaMetrics cluster](https://grafana.com/grafana/dashboards/11176)
|
||||
or [an alternative dashboard for VictoriaMetrics cluster](https://grafana.com/grafana/dashboards/11831).
|
||||
Graphs on these dashboards contain useful hints - hover the `i` icon at the top left corner of each graph in order to read it.
|
||||
|
||||
If you use Google Cloud Managed Prometheus for scraping metrics from VictoriaMetrics components, then pass `-metrics.exposeMetadata`
|
||||
|
||||
@@ -1768,6 +1768,8 @@ _Please note, never use loadbalancer address for scraping metrics. All the monit
|
||||
|
||||
Official Grafana dashboards available for [single-node](https://grafana.com/grafana/dashboards/10229)
|
||||
and [clustered](https://grafana.com/grafana/dashboards/11176) VictoriaMetrics.
|
||||
See an [alternative dashboard for clustered VictoriaMetrics](https://grafana.com/grafana/dashboards/11831)
|
||||
created by community.
|
||||
|
||||
Graphs on the dashboards contain useful hints - hover the `i` icon in the top left corner of each graph to read it.
|
||||
|
||||
|
||||
@@ -27,17 +27,16 @@ See also [LTS releases](https://docs.victoriametrics.com/victoriametrics/lts-rel
|
||||
* FEATURE: [vmbackup](https://docs.victoriametrics.com/vmbackup/), [vmbackupmanager](https://docs.victoriametrics.com/vmbackupmanager/): add an ability to set objects metadata (and tags for S3-compatible storage) when uploading backups by using `-objectMetadata` and `-s3ObjectTags` command-line flags. See [#8010](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/8010).
|
||||
* FEATURE: `vmselect` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/cluster-victoriametrics/): allow disabling tenant cache for [multitenant read queries](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multitenancy) by using `-search.disableCache` or `-search.tenantCacheExpireDuration=0` command-line flags, or by adding `nocache=1` query parameter. It can be useful for debugging purposes and in cases of frequent tenants creation.
|
||||
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/cluster-victoriametrics/): fixed a regression in downsampling logic introduced in [#7440](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/7440) and released in [v1.106.0](https://github.com/VictoriaMetrics/VictoriaMetrics/releases/tag/v1.106.0), where downsampling rules with filters `filter:offset:interval` could be incorrectly skipped in favor of unfiltered rules `offset:interval`. See [#8969](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/8969).
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): properly apply `rententionFilter` on flag value changes. Previously, it ignored any `filter` value changes for historical data. See [#8885](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/8885) for details.
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmselect` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/cluster-victoriametrics/): prevent panic caused by invalid label name in metric relabeling debugging interface. Error is now properly propagated and displayed in the interface. See [#8661](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/8661).
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): schedule a single background merge thread for merging historical data. Before, background merge could use extra resources without providing any benefit. See [#4592](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/4592) issue for details.
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): properly load [metric names stats tracker](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#track-ingested-metrics-usage) state from disk. Now it ignores corrupted `metric_usage_tracker` file content and init tracker with empty state in the same way as other caches loaded. See [9074](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9074) issue for details.
|
||||
* BUGFIX: `vmselect` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): fix inconsistent behaviour of tenants cache when using [multi-tenant reads](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multitenancy-via-labels). Previously, `vmselect` could use cached list of tenants which covered only part of the requested time range. That would lead to incomplete query results. See [#9042](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9042).
|
||||
* BUGFIX: `vmselect` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): remove tenant labels `vm_account_id` and `vm_project_id` from [exported data](https://docs.victoriametrics.com/#how-to-export-time-series) if tenant info was [specified in URL](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#url-format). These labels will be present only if export is done via [/multitenant/ endpoint](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multitenancy-via-labels), as such response could contain series belonging to different tenants. This change also fixes inconsistency in vmctl's [cluster-to-cluster migration mode](https://docs.victoriametrics.com/victoriametrics/vmctl/#cluster-to-cluster-migration-mode) - see [#9016](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9016) for details. Thank @fxrlv for the bug report.
|
||||
* BUGFIX: [vmgateway](https://docs.victoriametrics.com/victoriametrics/vmgateway/): add missing vmselect `vmui` related routes to the authorized requests routing. See [#9003](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9003) issue for details.
|
||||
* BUGFIX: [vmctl](https://docs.victoriametrics.com/victoriametrics/vmctl/): enable dual-stack network mode for `vmctl`connections by default. This allows connecting to IPv6 endpoints as it was not possible previously. See [#9116](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9116).
|
||||
* BUGFIX: [vmalert-tool](https://docs.victoriametrics.com/victoriametrics/vmalert-tool/): fix access conflicts for the temporary test folder when multiple users run tests on the same host. Thanks to @evkuzin for the [PR 9015](https://github.com/VictoriaMetrics/VictoriaMetrics/pull/9015).
|
||||
* BUGFIX: [vmalert-tool](https://docs.victoriametrics.com/victoriametrics/vmalert-tool/): fix access conflicts for the temporary test folder when multiple users run tests on the same host. Thanks to @evkuzin for the [pull request](https://github.com/VictoriaMetrics/VictoriaMetrics/pull/9015).
|
||||
* BUGFIX: [alerts](https://github.com/VictoriaMetrics/VictoriaMetrics/blob/master/deployment/docker/rules): fix the alerting rule `ScrapePoolHasNoTargets`. Previously, it may cause false positive in [sharding mode](https://docs.victoriametrics.com/victoriametrics/vmagent/#scraping-big-number-of-targets).
|
||||
* BUGFIX: [vmgateway](https://docs.victoriametrics.com/victoriametrics/vmgateway/): add missing vmselect `vmui` related routes to the authorized requests routing. See [9003](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9003) issue for details.
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): properly load [metric names stats tracker](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/#track-ingested-metrics-usage) state from disk. Now it ignores corrupted `metric_usage_tracker` file content and init tracker with empty state in the same way as other caches loaded. See [9074](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9074) issue for details.
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/cluster-victoriametrics/): fixed a regression in downsampling logic introduced in [#7440](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/7440) and released in [v1.106.0](https://github.com/VictoriaMetrics/VictoriaMetrics/releases/tag/v1.106.0), where downsampling rules with filters `filter:offset:interval` could be incorrectly skipped in favor of unfiltered rules `offset:interval`. See [#8969](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/8969).
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/victoriametrics/single-server-victoriametrics/) and `vmselect` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/cluster-victoriametrics/): prevent panic caused by invalid label name in metric relabeling debugging interface. Error is now properly propagated and displayed in the interface. See [#8661](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/8661).
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): properly apply `rententionFilter` on flag value changes. Previously, it ignored any `filter` value changes for historical data. See [this issue](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/8885) for details.
|
||||
* BUGFIX: [vmsingle](https://docs.victoriametrics.com/single-server-victoriametrics/) and `vmstorage` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): schedule a single background merge thread for merging historical data. See [4592](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/4592) issue for details.
|
||||
* BUGFIX: `vmselect` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): remove tenant labels `vm_account_id` and `vm_project_id` from [exported data](https://docs.victoriametrics.com/#how-to-export-time-series) if tenant info was [specified in URL](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#url-format). These labels will be present only if export is done via [/multitenant/ endpoint](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multitenancy-via-labels), as such response could contain series belonging to different tenants. This change also fixes inconsistency in vmctl's [cluster-to-cluster migration mode](https://docs.victoriametrics.com/victoriametrics/vmctl/#cluster-to-cluster-migration-mode) - see [#9016](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9016) for details. Thank @fxrlv for the bug report.
|
||||
* BUGFIX: `vmselect` in [VictoriaMetrics cluster](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/): fix inconsistent behaviour of tenants cache when using [multi-tenant reads](https://docs.victoriametrics.com/victoriametrics/cluster-victoriametrics/#multitenancy-via-labels). Previously, `vmselect` could use cached list of tenants which covered only part of the requested time range. That would lead to incomplete query results. See [#9042](https://github.com/VictoriaMetrics/VictoriaMetrics/issues/9042).
|
||||
|
||||
## [v1.118.0](https://github.com/VictoriaMetrics/VictoriaMetrics/releases/tag/v1.118.0)
|
||||
|
||||
|
||||
4
go.mod
4
go.mod
@@ -135,9 +135,7 @@ require (
|
||||
github.com/prometheus/sigv4 v0.2.0 // indirect
|
||||
github.com/puzpuzpuz/xsync/v3 v3.5.1 // indirect
|
||||
github.com/rivo/uniseg v0.4.7 // indirect
|
||||
github.com/rogpeppe/go-internal v1.14.1 // indirect
|
||||
github.com/russross/blackfriday/v2 v2.1.0 // indirect
|
||||
github.com/spf13/pflag v1.0.6 // indirect
|
||||
github.com/stretchr/testify v1.10.0 // indirect
|
||||
github.com/valyala/bytebufferpool v1.0.0 // indirect
|
||||
github.com/xrash/smetrics v0.0.0-20240521201337-686a1a2994c1 // indirect
|
||||
@@ -182,5 +180,3 @@ require (
|
||||
k8s.io/utils v0.0.0-20250502105355-0f33e8f1c979 // indirect
|
||||
sigs.k8s.io/yaml v1.4.0 // indirect
|
||||
)
|
||||
|
||||
tool github.com/valyala/quicktemplate/qtc
|
||||
|
||||
8
go.sum
8
go.sum
@@ -332,14 +332,14 @@ github.com/redis/go-redis/v9 v9.8.0/go.mod h1:huWgSWd8mW6+m0VPhJjSSQ+d6Nh1VICQ6Q
|
||||
github.com/rivo/uniseg v0.2.0/go.mod h1:J6wj4VEh+S6ZtnVlnTBMWIodfgj8LQOQFoIToxlJtxc=
|
||||
github.com/rivo/uniseg v0.4.7 h1:WUdvkW8uEhrYfLC4ZzdpI2ztxP1I582+49Oc5Mq64VQ=
|
||||
github.com/rivo/uniseg v0.4.7/go.mod h1:FN3SvrM+Zdj16jyLfmOkMNblXMcoc8DfTHruCPUcx88=
|
||||
github.com/rogpeppe/go-internal v1.14.1 h1:UQB4HGPB6osV0SQTLymcB4TgvyWu6ZyliaW0tI/otEQ=
|
||||
github.com/rogpeppe/go-internal v1.14.1/go.mod h1:MaRKkUm5W0goXpeCfT7UZI6fk/L7L7so1lCWt35ZSgc=
|
||||
github.com/rogpeppe/go-internal v1.13.1 h1:KvO1DLK/DRN07sQ1LQKScxyZJuNnedQ5/wKSR38lUII=
|
||||
github.com/rogpeppe/go-internal v1.13.1/go.mod h1:uMEvuHeurkdAXX61udpOXGD/AzZDWNMNyH2VO9fmH0o=
|
||||
github.com/russross/blackfriday/v2 v2.1.0 h1:JIOH55/0cWyOuilr9/qlrm0BSXldqnqwMsf35Ld67mk=
|
||||
github.com/russross/blackfriday/v2 v2.1.0/go.mod h1:+Rmxgy9KzJVeS9/2gXHxylqXiyQDYRxCVz55jmeOWTM=
|
||||
github.com/scaleway/scaleway-sdk-go v1.0.0-beta.32 h1:4+LP7qmsLSGbmc66m1s5dKRMBwztRppfxFKlYqYte/c=
|
||||
github.com/scaleway/scaleway-sdk-go v1.0.0-beta.32/go.mod h1:kzh+BSAvpoyHHdHBCDhmSWtBc1NbLMZ2lWHqnBoxFks=
|
||||
github.com/spf13/pflag v1.0.6 h1:jFzHGLGAlb3ruxLB8MhbI6A8+AQX/2eW4qeyNZXNp2o=
|
||||
github.com/spf13/pflag v1.0.6/go.mod h1:McXfInJRrz4CZXVZOBLb0bTZqETkiAhM9Iw0y3An2Bg=
|
||||
github.com/spf13/pflag v1.0.5 h1:iy+VFUOCP1a+8yFto/drg2CJ5u0yRoB7fZw3DKv/JXA=
|
||||
github.com/spf13/pflag v1.0.5/go.mod h1:McXfInJRrz4CZXVZOBLb0bTZqETkiAhM9Iw0y3An2Bg=
|
||||
github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
|
||||
github.com/stretchr/objx v0.4.0/go.mod h1:YvHI0jy2hoMjB+UWwv71VJQ9isScKT/TqJzVSSt89Yw=
|
||||
github.com/stretchr/objx v0.5.0/go.mod h1:Yh+to48EsGEfYuaHDzXPcE3xhTkx73EhmCGUpEOglKo=
|
||||
|
||||
@@ -1,10 +0,0 @@
|
||||
package atomicutil
|
||||
|
||||
import (
|
||||
"unsafe"
|
||||
|
||||
"golang.org/x/sys/cpu"
|
||||
)
|
||||
|
||||
// CacheLineSize is the size of a CPU cache line
|
||||
const CacheLineSize = unsafe.Sizeof(cpu.CacheLinePad{})
|
||||
@@ -19,8 +19,8 @@ type Slice[T any] struct {
|
||||
type itemPadded[T any] struct {
|
||||
x T
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with cache line size >= 128.
|
||||
_ [128]byte
|
||||
}
|
||||
|
||||
// Get returns *T item for the given workerID in a goroutine-safe manner.
|
||||
|
||||
@@ -2,16 +2,15 @@ package atomicutil
|
||||
|
||||
import (
|
||||
"sync/atomic"
|
||||
"unsafe"
|
||||
)
|
||||
|
||||
// Uint64 is like atomic.Uint64, but is protected from false sharing.
|
||||
type Uint64 struct {
|
||||
// The padding prevents false sharing with the previous memory location
|
||||
_ [CacheLineSize - unsafe.Sizeof(atomic.Uint64{})%CacheLineSize]byte
|
||||
// The padding prevents false sharing with the previous memory location on widespread platforms with cache line size >= 128.
|
||||
_ [128]byte
|
||||
|
||||
atomic.Uint64
|
||||
|
||||
// The padding prevents false sharing with the next memory location
|
||||
_ [CacheLineSize - unsafe.Sizeof(atomic.Uint64{})%CacheLineSize]byte
|
||||
// The padding prevents false sharing with the next memory location on widespread platforms with cache line size >= 128.
|
||||
_ [128]byte
|
||||
}
|
||||
|
||||
@@ -692,7 +692,7 @@ type rowsBufferShard struct {
|
||||
flushTimer *time.Timer
|
||||
|
||||
// padding for preventing false sharing
|
||||
_ [atomicutil.CacheLineSize]byte
|
||||
_ [128]byte
|
||||
}
|
||||
|
||||
func (rb *rowsBuffer) flush() {
|
||||
|
||||
@@ -6,7 +6,6 @@ import (
|
||||
|
||||
"github.com/cespare/xxhash/v2"
|
||||
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/atomicutil"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/bytesutil"
|
||||
)
|
||||
|
||||
@@ -34,8 +33,8 @@ type hitsMapAdaptive struct {
|
||||
type hitsMapShard struct {
|
||||
hitsMap
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [atomicutil.CacheLineSize - unsafe.Sizeof(hitsMap{})%atomicutil.CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with 128 mod (cache line size) = 0 .
|
||||
_ [128 - unsafe.Sizeof(hitsMap{})%128]byte
|
||||
}
|
||||
|
||||
// the maximum number of values to track in hitsMapAdaptive.hm before switching to hitsMapAdaptive.hmShards
|
||||
|
||||
@@ -378,8 +378,8 @@ type pipeStatsProcessorShard struct {
|
||||
type pipeStatsGroupMapShard struct {
|
||||
pipeStatsGroupMap
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [atomicutil.CacheLineSize - unsafe.Sizeof(pipeStatsGroupMap{})%atomicutil.CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with 128 mod (cache line size) = 0 .
|
||||
_ [128 - unsafe.Sizeof(pipeStatsGroupMap{})%128]byte
|
||||
}
|
||||
|
||||
// the maximum number of groups to track in pipeStatsProcessorShard.groupMap before switching to pipeStatsProcessorShard.groupMapShards
|
||||
|
||||
@@ -217,8 +217,9 @@ type rawItemsShardNopad struct {
|
||||
type rawItemsShard struct {
|
||||
rawItemsShardNopad
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [atomicutil.CacheLineSize - unsafe.Sizeof(rawItemsShardNopad{})%atomicutil.CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with
|
||||
// 128 mod (cache line size) = 0 .
|
||||
_ [128 - unsafe.Sizeof(rawItemsShardNopad{})%128]byte
|
||||
}
|
||||
|
||||
func (ris *rawItemsShard) Len() int {
|
||||
|
||||
@@ -80,7 +80,7 @@ func IsErrMissingPort(err error) bool {
|
||||
// It returns the normalized address in the form "host:port".
|
||||
// It is expected that addr is in the form "host" or "host:port".
|
||||
func NormalizeAddr(addr string, defaultPort int) (string, error) {
|
||||
if strings.Contains(addr, "/") {
|
||||
if strings.Index(addr, "/") > 0 {
|
||||
return "", fmt.Errorf("invalid address %q; expected format: host:port", addr)
|
||||
}
|
||||
|
||||
|
||||
@@ -65,5 +65,4 @@ func TestNormalizeAddrError(t *testing.T) {
|
||||
f("http://127.0.0.1:80")
|
||||
f("http://vmstorage-0.svc.cluster.local.")
|
||||
f("http://vmstorage-0.svc.cluster.local.:80")
|
||||
f("/vmstorage-0.svc.cluster.local.:80")
|
||||
}
|
||||
|
||||
@@ -42,11 +42,6 @@ func NewTCPListener(name, addr string, useProxyProtocol bool, tlsConfig *tls.Con
|
||||
return tln, err
|
||||
}
|
||||
|
||||
// EnableIPv6 enables IPv6 for dialing and listening.
|
||||
func EnableIPv6() {
|
||||
*enableTCP6 = true
|
||||
}
|
||||
|
||||
// TCP6Enabled returns true if dialing and listening for IPv4 TCP is enabled.
|
||||
func TCP6Enabled() bool {
|
||||
return *enableTCP6
|
||||
|
||||
@@ -13,7 +13,6 @@ import (
|
||||
"time"
|
||||
"unsafe"
|
||||
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/atomicutil"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/cgroup"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/encoding"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/fs"
|
||||
@@ -518,8 +517,9 @@ type rawRowsShardNopad struct {
|
||||
type rawRowsShard struct {
|
||||
rawRowsShardNopad
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [atomicutil.CacheLineSize - unsafe.Sizeof(rawRowsShardNopad{})%atomicutil.CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with
|
||||
// 128 mod (cache line size) = 0 .
|
||||
_ [128 - unsafe.Sizeof(rawRowsShardNopad{})%128]byte
|
||||
}
|
||||
|
||||
func (rrs *rawRowsShard) Len() int {
|
||||
|
||||
@@ -8,7 +8,6 @@ import (
|
||||
"github.com/VictoriaMetrics/metrics"
|
||||
"github.com/cespare/xxhash/v2"
|
||||
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/atomicutil"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/bytesutil"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/decimal"
|
||||
"github.com/VictoriaMetrics/VictoriaMetrics/lib/slicesutil"
|
||||
@@ -25,8 +24,9 @@ type dedupAggr struct {
|
||||
type dedupAggrShard struct {
|
||||
dedupAggrShardNopad
|
||||
|
||||
// The padding prevents false sharing
|
||||
_ [atomicutil.CacheLineSize - unsafe.Sizeof(dedupAggrShardNopad{})%atomicutil.CacheLineSize]byte
|
||||
// The padding prevents false sharing on widespread platforms with
|
||||
// 128 mod (cache line size) = 0 .
|
||||
_ [128 - unsafe.Sizeof(dedupAggrShardNopad{})%128]byte
|
||||
}
|
||||
|
||||
type dedupAggrState struct {
|
||||
|
||||
205
vendor/github.com/valyala/quicktemplate/parser/functype.go
generated
vendored
205
vendor/github.com/valyala/quicktemplate/parser/functype.go
generated
vendored
@@ -1,205 +0,0 @@
|
||||
package parser
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"go/ast"
|
||||
goparser "go/parser"
|
||||
"strings"
|
||||
)
|
||||
|
||||
type funcType struct {
|
||||
name string
|
||||
defPrefix string
|
||||
callPrefix string
|
||||
argNames string
|
||||
args string
|
||||
}
|
||||
|
||||
func parseFuncDef(b []byte) (*funcType, error) {
|
||||
defStr := string(b)
|
||||
|
||||
// extract func name
|
||||
n := strings.Index(defStr, "(")
|
||||
if n < 0 {
|
||||
return nil, fmt.Errorf("cannot find '(' in function definition")
|
||||
}
|
||||
name := defStr[:n]
|
||||
defStr = defStr[n+1:]
|
||||
defPrefix := ""
|
||||
callPrefix := ""
|
||||
if len(name) == 0 {
|
||||
// Either empty func name or valid method definition. Let's check.
|
||||
|
||||
// parse method receiver
|
||||
n = strings.Index(defStr, ")")
|
||||
if n < 0 {
|
||||
return nil, fmt.Errorf("cannot find ')' in func")
|
||||
}
|
||||
recvStr := defStr[:n]
|
||||
defStr = defStr[n+1:]
|
||||
exprStr := fmt.Sprintf("func (%s)", recvStr)
|
||||
expr, err := goparser.ParseExpr(exprStr)
|
||||
if err != nil {
|
||||
return nil, fmt.Errorf("invalid method definition: %s", err)
|
||||
}
|
||||
ft := expr.(*ast.FuncType)
|
||||
if len(ft.Params.List) != 1 || len(ft.Params.List[0].Names) != 1 {
|
||||
// method receiver must contain only one param
|
||||
return nil, fmt.Errorf("missing func or method name")
|
||||
}
|
||||
recvName := ft.Params.List[0].Names[0].Name
|
||||
defPrefix = fmt.Sprintf("(%s) ", recvStr)
|
||||
callPrefix = recvName + "."
|
||||
|
||||
// extract method name
|
||||
n = strings.Index(defStr, "(")
|
||||
if n < 0 {
|
||||
return nil, fmt.Errorf("missing func name")
|
||||
}
|
||||
name = string(stripLeadingSpace([]byte(defStr[:n])))
|
||||
if len(name) == 0 {
|
||||
return nil, fmt.Errorf("missing method name")
|
||||
}
|
||||
defStr = defStr[n+1:]
|
||||
}
|
||||
|
||||
// validate and collect func args
|
||||
if len(defStr) == 0 || defStr[len(defStr)-1] != ')' {
|
||||
return nil, fmt.Errorf("missing ')' at the end of func")
|
||||
}
|
||||
args := defStr[:len(defStr)-1]
|
||||
exprStr := fmt.Sprintf("func (%s)", args)
|
||||
expr, err := goparser.ParseExpr(exprStr)
|
||||
if err != nil {
|
||||
return nil, fmt.Errorf("invalid func args: %s", err)
|
||||
}
|
||||
ft := expr.(*ast.FuncType)
|
||||
if ft.Results != nil {
|
||||
return nil, fmt.Errorf("func mustn't return any results")
|
||||
}
|
||||
|
||||
// extract arg names
|
||||
var tmp []string
|
||||
for _, f := range ft.Params.List {
|
||||
if len(f.Names) == 0 {
|
||||
return nil, fmt.Errorf("func cannot contain untyped arguments")
|
||||
}
|
||||
for _, n := range f.Names {
|
||||
if n == nil {
|
||||
return nil, fmt.Errorf("func cannot contain untyped arguments")
|
||||
}
|
||||
if _, isVariadic := f.Type.(*ast.Ellipsis); isVariadic {
|
||||
tmp = append(tmp, n.Name+"...")
|
||||
} else {
|
||||
tmp = append(tmp, n.Name)
|
||||
}
|
||||
}
|
||||
}
|
||||
argNames := strings.Join(tmp, ", ")
|
||||
|
||||
if len(args) > 0 {
|
||||
args = ", " + args
|
||||
}
|
||||
if len(argNames) > 0 {
|
||||
argNames = ", " + argNames
|
||||
}
|
||||
return &funcType{
|
||||
name: name,
|
||||
defPrefix: defPrefix,
|
||||
callPrefix: callPrefix,
|
||||
argNames: argNames,
|
||||
args: args,
|
||||
}, nil
|
||||
}
|
||||
|
||||
func parseFuncCall(b []byte) (*funcType, error) {
|
||||
exprStr := string(b)
|
||||
expr, err := goparser.ParseExpr(exprStr)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
ce, ok := expr.(*ast.CallExpr)
|
||||
if !ok {
|
||||
return nil, fmt.Errorf("missing function call")
|
||||
}
|
||||
callPrefix, name, err := getCallName(ce)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
argNames := exprStr[ce.Lparen : ce.Rparen-1]
|
||||
|
||||
if len(argNames) > 0 {
|
||||
argNames = ", " + argNames
|
||||
}
|
||||
return &funcType{
|
||||
name: name,
|
||||
callPrefix: callPrefix,
|
||||
argNames: argNames,
|
||||
}, nil
|
||||
}
|
||||
|
||||
func (f *funcType) DefStream(dst string) string {
|
||||
return fmt.Sprintf("%s%s%s(%s *qt%s.Writer%s)", f.defPrefix, f.prefixStream(), f.name, dst, mangleSuffix, f.args)
|
||||
}
|
||||
|
||||
func (f *funcType) CallStream(dst string) string {
|
||||
return fmt.Sprintf("%s%s%s(%s%s)", f.callPrefix, f.prefixStream(), f.name, dst, f.argNames)
|
||||
}
|
||||
|
||||
func (f *funcType) DefWrite(dst string) string {
|
||||
return fmt.Sprintf("%s%s%s(%s qtio%s.Writer%s)", f.defPrefix, f.prefixWrite(), f.name, dst, mangleSuffix, f.args)
|
||||
}
|
||||
|
||||
func (f *funcType) CallWrite(dst string) string {
|
||||
return fmt.Sprintf("%s%s%s(%s%s)", f.callPrefix, f.prefixWrite(), f.name, dst, f.argNames)
|
||||
}
|
||||
|
||||
func (f *funcType) DefString() string {
|
||||
args := f.args
|
||||
if len(args) > 0 {
|
||||
// skip the first ', '
|
||||
args = args[2:]
|
||||
}
|
||||
return fmt.Sprintf("%s%s(%s) string", f.defPrefix, f.name, args)
|
||||
}
|
||||
|
||||
func (f *funcType) prefixWrite() string {
|
||||
s := "write"
|
||||
if isUpper(f.name[0]) {
|
||||
s = "Write"
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
func (f *funcType) prefixStream() string {
|
||||
s := "stream"
|
||||
if isUpper(f.name[0]) {
|
||||
s = "Stream"
|
||||
}
|
||||
return s
|
||||
}
|
||||
|
||||
func getCallName(ce *ast.CallExpr) (string, string, error) {
|
||||
callPrefix := ""
|
||||
name := ""
|
||||
expr := ce.Fun
|
||||
for {
|
||||
switch x := expr.(type) {
|
||||
case *ast.Ident:
|
||||
if len(callPrefix) == 0 && len(name) == 0 {
|
||||
return "", x.Name, nil
|
||||
}
|
||||
callPrefix = x.Name + "." + callPrefix
|
||||
return callPrefix, name, nil
|
||||
case *ast.SelectorExpr:
|
||||
if len(name) == 0 {
|
||||
name = x.Sel.Name
|
||||
} else {
|
||||
callPrefix = x.Sel.Name + "." + callPrefix
|
||||
}
|
||||
expr = x.X
|
||||
default:
|
||||
return "", "", fmt.Errorf("unexpected function name")
|
||||
}
|
||||
}
|
||||
}
|
||||
921
vendor/github.com/valyala/quicktemplate/parser/parser.go
generated
vendored
921
vendor/github.com/valyala/quicktemplate/parser/parser.go
generated
vendored
@@ -1,921 +0,0 @@
|
||||
package parser
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"go/ast"
|
||||
goparser "go/parser"
|
||||
gotoken "go/token"
|
||||
"io"
|
||||
"path/filepath"
|
||||
"strconv"
|
||||
"strings"
|
||||
)
|
||||
|
||||
type parser struct {
|
||||
s *scanner
|
||||
w io.Writer
|
||||
packageName string
|
||||
skipLineComments bool
|
||||
prefix string
|
||||
forDepth int
|
||||
switchDepth int
|
||||
skipOutputDepth int
|
||||
|
||||
importsUseEmitted bool
|
||||
packageNameEmitted bool
|
||||
}
|
||||
|
||||
// Parse parses the contents of the supplied reader, writing generated code to
|
||||
// the supplied writer. Uses filename as the source file for line comments, and
|
||||
// pkg as the Go package name.
|
||||
func Parse(w io.Writer, r io.Reader, filename, pkg string) error {
|
||||
return parse(w, r, filename, pkg, false)
|
||||
}
|
||||
|
||||
// ParseNoLineComments is the same as Parse, but does not write line comments.
|
||||
func ParseNoLineComments(w io.Writer, r io.Reader, filename, pkg string) error {
|
||||
return parse(w, r, filename, pkg, true)
|
||||
}
|
||||
|
||||
func parse(w io.Writer, r io.Reader, filename, pkg string, skipLineComments bool) error {
|
||||
p := &parser{
|
||||
s: newScanner(r, filename),
|
||||
w: w,
|
||||
packageName: pkg,
|
||||
skipLineComments: skipLineComments,
|
||||
}
|
||||
return p.parseTemplate()
|
||||
}
|
||||
|
||||
func (p *parser) parseTemplate() error {
|
||||
s := p.s
|
||||
fmt.Fprintf(p.w, `// Code generated by qtc from %q. DO NOT EDIT.
|
||||
// See https://github.com/valyala/quicktemplate for details.
|
||||
|
||||
`,
|
||||
filepath.Base(s.filePath))
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
p.emitComment(t.Value)
|
||||
case tagName:
|
||||
switch string(t.Value) {
|
||||
case "package":
|
||||
if p.packageNameEmitted {
|
||||
return fmt.Errorf("package name must be at the top of the template. Found at %s", s.Context())
|
||||
}
|
||||
if err := p.parsePackageName(); err != nil {
|
||||
return err
|
||||
}
|
||||
case "import":
|
||||
p.emitPackageName()
|
||||
if p.importsUseEmitted {
|
||||
return fmt.Errorf("imports must be at the top of the template. Found at %s", s.Context())
|
||||
}
|
||||
if err := p.parseImport(); err != nil {
|
||||
return err
|
||||
}
|
||||
default:
|
||||
p.emitPackageName()
|
||||
p.emitImportsUse()
|
||||
switch string(t.Value) {
|
||||
case "interface", "iface":
|
||||
if err := p.parseInterface(); err != nil {
|
||||
return err
|
||||
}
|
||||
case "code":
|
||||
if err := p.parseTemplateCode(); err != nil {
|
||||
return err
|
||||
}
|
||||
case "func":
|
||||
if err := p.parseFunc(); err != nil {
|
||||
return err
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected tag found outside func: %q at %s", t.Value, s.Context())
|
||||
}
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found %s outside func at %s", t, s.Context())
|
||||
}
|
||||
}
|
||||
p.emitImportsUse()
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse template: %s", err)
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) emitPackageName() {
|
||||
if !p.packageNameEmitted {
|
||||
p.Printf("package %s\n", p.packageName)
|
||||
p.packageNameEmitted = true
|
||||
}
|
||||
}
|
||||
|
||||
func (p *parser) emitComment(comment []byte) {
|
||||
isFirstNonemptyLine := false
|
||||
for len(comment) > 0 {
|
||||
n := bytes.IndexByte(comment, '\n')
|
||||
if n < 0 {
|
||||
n = len(comment)
|
||||
}
|
||||
line := stripTrailingSpace(comment[:n])
|
||||
if bytes.HasPrefix(line, []byte("//")) {
|
||||
line = line[2:]
|
||||
if len(line) > 0 && isSpace(line[0]) {
|
||||
line = line[1:]
|
||||
}
|
||||
}
|
||||
if len(line) == 0 {
|
||||
if isFirstNonemptyLine {
|
||||
fmt.Fprintf(p.w, "//\n")
|
||||
}
|
||||
} else {
|
||||
fmt.Fprintf(p.w, "// %s\n", line)
|
||||
isFirstNonemptyLine = true
|
||||
}
|
||||
|
||||
if n < len(comment) {
|
||||
comment = comment[n+1:]
|
||||
} else {
|
||||
comment = comment[n:]
|
||||
}
|
||||
}
|
||||
fmt.Fprintf(p.w, "\n")
|
||||
}
|
||||
|
||||
func (p *parser) emitImportsUse() {
|
||||
if p.importsUseEmitted {
|
||||
return
|
||||
}
|
||||
p.Printf(`import (
|
||||
qtio%s "io"
|
||||
|
||||
qt%s "github.com/valyala/quicktemplate"
|
||||
)
|
||||
`, mangleSuffix, mangleSuffix)
|
||||
p.Printf(`var (
|
||||
_ = qtio%s.Copy
|
||||
_ = qt%s.AcquireByteBuffer
|
||||
)
|
||||
`, mangleSuffix, mangleSuffix)
|
||||
p.importsUseEmitted = true
|
||||
}
|
||||
|
||||
func (p *parser) parseFunc() error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
funcStr := "func " + string(t.Value)
|
||||
f, err := parseFuncDef(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error in %q at %s: %s", funcStr, s.Context(), err)
|
||||
}
|
||||
p.emitFuncStart(f)
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
p.emitText(t.Value)
|
||||
case tagName:
|
||||
ok, err := p.tryParseCommonTags(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error in %q: %s", funcStr, err)
|
||||
}
|
||||
if ok {
|
||||
continue
|
||||
}
|
||||
switch string(t.Value) {
|
||||
case "endfunc":
|
||||
if err = skipTagContents(s); err != nil {
|
||||
return err
|
||||
}
|
||||
p.emitFuncEnd(f)
|
||||
return nil
|
||||
default:
|
||||
return fmt.Errorf("unexpected tag found in %q: %q at %s", funcStr, t.Value, s.Context())
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found when parsing %q: %s at %s", funcStr, t, s.Context())
|
||||
}
|
||||
}
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse %q: %s", funcStr, err)
|
||||
}
|
||||
return fmt.Errorf("cannot find endfunc tag for %q at %s", funcStr, s.Context())
|
||||
}
|
||||
|
||||
func (p *parser) parseFor() error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
forStr := "for " + string(t.Value)
|
||||
if err = validateForStmt(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid statement %q at %s: %s", forStr, s.Context(), err)
|
||||
}
|
||||
p.Printf("for %s {", t.Value)
|
||||
p.prefix += "\t"
|
||||
p.forDepth++
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
p.emitText(t.Value)
|
||||
case tagName:
|
||||
ok, err := p.tryParseCommonTags(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error in %q: %s", forStr, err)
|
||||
}
|
||||
if ok {
|
||||
continue
|
||||
}
|
||||
switch string(t.Value) {
|
||||
case "endfor":
|
||||
if err = skipTagContents(s); err != nil {
|
||||
return err
|
||||
}
|
||||
p.forDepth--
|
||||
p.prefix = p.prefix[1:]
|
||||
p.Printf("}")
|
||||
return nil
|
||||
default:
|
||||
return fmt.Errorf("unexpected tag found in %q: %q at %s", forStr, t.Value, s.Context())
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found when parsing %q: %s at %s", forStr, t, s.Context())
|
||||
}
|
||||
}
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse %q: %s", forStr, err)
|
||||
}
|
||||
return fmt.Errorf("cannot find endfor tag for %q at %s", forStr, s.Context())
|
||||
}
|
||||
|
||||
func (p *parser) parseDefault() error {
|
||||
s := p.s
|
||||
if err := skipTagContents(s); err != nil {
|
||||
return err
|
||||
}
|
||||
stmtStr := "default"
|
||||
p.Printf("default:")
|
||||
p.prefix += "\t"
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
p.emitText(t.Value)
|
||||
case tagName:
|
||||
ok, err := p.tryParseCommonTags(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error in %q: %s", stmtStr, err)
|
||||
}
|
||||
if !ok {
|
||||
s.Rewind()
|
||||
p.prefix = p.prefix[1:]
|
||||
return nil
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found when parsing %q: %s at %s", stmtStr, t, s.Context())
|
||||
}
|
||||
}
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse %q: %s", stmtStr, err)
|
||||
}
|
||||
return fmt.Errorf("cannot find end of %q at %s", stmtStr, s.Context())
|
||||
}
|
||||
|
||||
func (p *parser) parseCase(switchValue string) error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
caseStr := "case " + string(t.Value)
|
||||
if err = validateCaseStmt(switchValue, t.Value); err != nil {
|
||||
return fmt.Errorf("invalid statement %q at %s: %s", caseStr, s.Context(), err)
|
||||
}
|
||||
p.Printf("case %s:", t.Value)
|
||||
p.prefix += "\t"
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
p.emitText(t.Value)
|
||||
case tagName:
|
||||
ok, err := p.tryParseCommonTags(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error in %q: %s", caseStr, err)
|
||||
}
|
||||
if !ok {
|
||||
s.Rewind()
|
||||
p.prefix = p.prefix[1:]
|
||||
return nil
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found when parsing %q: %s at %s", caseStr, t, s.Context())
|
||||
}
|
||||
}
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse %q: %s", caseStr, err)
|
||||
}
|
||||
return fmt.Errorf("cannot find end of %q at %s", caseStr, s.Context())
|
||||
}
|
||||
|
||||
func (p *parser) parseCat() error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
filename, err := strconv.Unquote(string(t.Value))
|
||||
if err != nil {
|
||||
return fmt.Errorf("invalid cat value %q at %s: %s", t.Value, s.Context(), err)
|
||||
}
|
||||
|
||||
data, err := readFile(s.filePath, filename)
|
||||
if err != nil {
|
||||
return fmt.Errorf("cannot cat file %q at %s: %s", filename, s.Context(), err)
|
||||
}
|
||||
p.emitText(data)
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) parseSwitch() error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
switchStr := "switch " + string(t.Value)
|
||||
if err = validateSwitchStmt(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid statement %q at %s: %s", switchStr, s.Context(), err)
|
||||
}
|
||||
p.Printf("switch %s {", t.Value)
|
||||
switchValue := string(t.Value)
|
||||
caseNum := 0
|
||||
defaultFound := false
|
||||
p.switchDepth++
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
if caseNum == 0 {
|
||||
comment := stripLeadingSpace(t.Value)
|
||||
if len(comment) > 0 {
|
||||
p.emitComment(comment)
|
||||
}
|
||||
} else {
|
||||
p.emitText(t.Value)
|
||||
}
|
||||
case tagName:
|
||||
switch string(t.Value) {
|
||||
case "endswitch":
|
||||
if caseNum == 0 {
|
||||
return fmt.Errorf("empty statement %q found at %s", switchStr, s.Context())
|
||||
}
|
||||
if err = skipTagContents(s); err != nil {
|
||||
return err
|
||||
}
|
||||
p.switchDepth--
|
||||
p.Printf("}")
|
||||
return nil
|
||||
case "case":
|
||||
caseNum++
|
||||
if err = p.parseCase(switchValue); err != nil {
|
||||
return err
|
||||
}
|
||||
case "default":
|
||||
if defaultFound {
|
||||
return fmt.Errorf("duplicate default tag found in %q at %s", switchStr, s.Context())
|
||||
}
|
||||
defaultFound = true
|
||||
caseNum++
|
||||
if err = p.parseDefault(); err != nil {
|
||||
return err
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected tag found in %q: %q at %s", switchStr, t.Value, s.Context())
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found when parsing %q: %s at %s", switchStr, t, s.Context())
|
||||
}
|
||||
}
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse %q: %s", switchStr, err)
|
||||
}
|
||||
return fmt.Errorf("cannot find endswitch tag for %q at %s", switchStr, s.Context())
|
||||
}
|
||||
|
||||
func (p *parser) parseIf() error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if len(t.Value) == 0 {
|
||||
return fmt.Errorf("empty if condition at %s", s.Context())
|
||||
}
|
||||
ifStr := "if " + string(t.Value)
|
||||
if err = validateIfStmt(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid statement %q at %s: %s", ifStr, s.Context(), err)
|
||||
}
|
||||
p.Printf("if %s {", t.Value)
|
||||
p.prefix += "\t"
|
||||
elseUsed := false
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
p.emitText(t.Value)
|
||||
case tagName:
|
||||
ok, err := p.tryParseCommonTags(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error in %q: %s", ifStr, err)
|
||||
}
|
||||
if ok {
|
||||
continue
|
||||
}
|
||||
switch string(t.Value) {
|
||||
case "endif":
|
||||
if err = skipTagContents(s); err != nil {
|
||||
return err
|
||||
}
|
||||
p.prefix = p.prefix[1:]
|
||||
p.Printf("}")
|
||||
return nil
|
||||
case "else":
|
||||
if elseUsed {
|
||||
return fmt.Errorf("duplicate else branch found for %q at %s", ifStr, s.Context())
|
||||
}
|
||||
if err = skipTagContents(s); err != nil {
|
||||
return err
|
||||
}
|
||||
p.prefix = p.prefix[1:]
|
||||
p.Printf("} else {")
|
||||
p.prefix += "\t"
|
||||
elseUsed = true
|
||||
case "elseif":
|
||||
if elseUsed {
|
||||
return fmt.Errorf("unexpected elseif branch found after else branch for %q at %s",
|
||||
ifStr, s.Context())
|
||||
}
|
||||
t, err = expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
p.prefix = p.prefix[1:]
|
||||
p.Printf("} else if %s {", t.Value)
|
||||
p.prefix += "\t"
|
||||
default:
|
||||
return fmt.Errorf("unexpected tag found in %q: %q at %s", ifStr, t.Value, s.Context())
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found when parsing %q: %s at %s", ifStr, t, s.Context())
|
||||
}
|
||||
}
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse %q: %s", ifStr, err)
|
||||
}
|
||||
return fmt.Errorf("cannot find endif tag for %q at %s", ifStr, s.Context())
|
||||
}
|
||||
|
||||
func (p *parser) tryParseCommonTags(tagBytes []byte) (bool, error) {
|
||||
tagNameStr, prec := splitTagNamePrec(string(tagBytes))
|
||||
switch tagNameStr {
|
||||
case "s", "v", "d", "dl", "dul", "f", "q", "z", "j", "u",
|
||||
"s=", "v=", "d=", "dl=", "dul=", "f=", "q=", "z=", "j=", "u=",
|
||||
"sz", "qz", "jz", "uz",
|
||||
"sz=", "qz=", "jz=", "uz=":
|
||||
if err := p.parseOutputTag(tagNameStr, prec); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "=", "=h", "=u", "=uh", "=q", "=qh", "=j", "=jh":
|
||||
if err := p.parseOutputFunc(tagNameStr); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "return":
|
||||
if err := p.skipAfterTag(tagNameStr); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "break":
|
||||
if p.forDepth <= 0 && p.switchDepth <= 0 {
|
||||
return false, fmt.Errorf("found break tag outside for loop and switch block")
|
||||
}
|
||||
if err := p.skipAfterTag(tagNameStr); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "continue":
|
||||
if p.forDepth <= 0 {
|
||||
return false, fmt.Errorf("found continue tag outside for loop")
|
||||
}
|
||||
if err := p.skipAfterTag(tagNameStr); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "code":
|
||||
if err := p.parseFuncCode(); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "for":
|
||||
if err := p.parseFor(); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "if":
|
||||
if err := p.parseIf(); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "switch":
|
||||
if err := p.parseSwitch(); err != nil {
|
||||
return false, err
|
||||
}
|
||||
case "cat":
|
||||
if err := p.parseCat(); err != nil {
|
||||
return false, err
|
||||
}
|
||||
default:
|
||||
return false, nil
|
||||
}
|
||||
return true, nil
|
||||
}
|
||||
|
||||
func splitTagNamePrec(tagName string) (string, int) {
|
||||
parts := strings.Split(tagName, ".")
|
||||
if len(parts) == 2 && parts[0] == "f" {
|
||||
p := parts[1]
|
||||
if strings.HasSuffix(p, "=") {
|
||||
p = p[:len(p)-1]
|
||||
}
|
||||
if len(p) == 0 {
|
||||
return "f", 0
|
||||
}
|
||||
prec, err := strconv.Atoi(p)
|
||||
if err == nil && prec >= 0 {
|
||||
return "f", prec
|
||||
}
|
||||
}
|
||||
return tagName, -1
|
||||
}
|
||||
|
||||
func (p *parser) skipAfterTag(tagStr string) error {
|
||||
s := p.s
|
||||
if err := skipTagContents(s); err != nil {
|
||||
return err
|
||||
}
|
||||
p.Printf("%s", tagStr)
|
||||
p.skipOutputDepth++
|
||||
defer func() {
|
||||
p.skipOutputDepth--
|
||||
}()
|
||||
for s.Next() {
|
||||
t := s.Token()
|
||||
switch t.ID {
|
||||
case text:
|
||||
// skip text
|
||||
case tagName:
|
||||
ok, err := p.tryParseCommonTags(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error when parsing contents after %q: %s", tagStr, err)
|
||||
}
|
||||
if ok {
|
||||
continue
|
||||
}
|
||||
switch string(t.Value) {
|
||||
case "endfunc", "endfor", "endif", "else", "elseif", "case", "default", "endswitch":
|
||||
s.Rewind()
|
||||
return nil
|
||||
default:
|
||||
return fmt.Errorf("unexpected tag found after %q: %q at %s", tagStr, t.Value, s.Context())
|
||||
}
|
||||
default:
|
||||
return fmt.Errorf("unexpected token found when parsing contents after %q: %s at %s", tagStr, t, s.Context())
|
||||
}
|
||||
}
|
||||
if err := s.LastError(); err != nil {
|
||||
return fmt.Errorf("cannot parse contents after %q: %s", tagStr, err)
|
||||
}
|
||||
return fmt.Errorf("cannot find closing tag after %q at %s", tagStr, s.Context())
|
||||
}
|
||||
|
||||
func (p *parser) parseInterface() error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
n := bytes.IndexByte(t.Value, '{')
|
||||
if n < 0 {
|
||||
return fmt.Errorf("missing '{' in interface at %s", s.Context())
|
||||
}
|
||||
ifname := string(stripTrailingSpace(t.Value[:n]))
|
||||
if len(ifname) == 0 {
|
||||
return fmt.Errorf("missing interface name at %s", s.Context())
|
||||
}
|
||||
p.Printf("type %s interface {", ifname)
|
||||
p.prefix = "\t"
|
||||
|
||||
tail := t.Value[n:]
|
||||
exprStr := fmt.Sprintf("interface %s", tail)
|
||||
expr, err := goparser.ParseExpr(exprStr)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error when parsing interface at %s: %s", s.Context(), err)
|
||||
}
|
||||
it, ok := expr.(*ast.InterfaceType)
|
||||
if !ok {
|
||||
return fmt.Errorf("unexpected interface type at %s: %T", s.Context(), expr)
|
||||
}
|
||||
methods := it.Methods.List
|
||||
if len(methods) == 0 {
|
||||
return fmt.Errorf("interface must contain at least one method at %s", s.Context())
|
||||
}
|
||||
|
||||
for _, m := range it.Methods.List {
|
||||
methodStr := exprStr[m.Pos()-1 : m.End()-1]
|
||||
f, err := parseFuncDef([]byte(methodStr))
|
||||
if err != nil {
|
||||
return fmt.Errorf("when when parsing %q at %s: %s", methodStr, s.Context(), err)
|
||||
}
|
||||
p.Printf("%s string", methodStr)
|
||||
p.Printf("%s", f.DefStream("qw"+mangleSuffix))
|
||||
p.Printf("%s", f.DefWrite("qq"+mangleSuffix))
|
||||
}
|
||||
p.prefix = ""
|
||||
p.Printf("}")
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) parsePackageName() error {
|
||||
t, err := expectTagContents(p.s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if len(t.Value) == 0 {
|
||||
return fmt.Errorf("empty package name found at %s", p.s.Context())
|
||||
}
|
||||
if err = validatePackageName(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid package name found at %s: %s", p.s.Context(), err)
|
||||
}
|
||||
p.packageName = string(t.Value)
|
||||
p.emitPackageName()
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) parseImport() error {
|
||||
t, err := expectTagContents(p.s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if len(t.Value) == 0 {
|
||||
return fmt.Errorf("empty import found at %s", p.s.Context())
|
||||
}
|
||||
if err = validateImport(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid import found at %s: %s", p.s.Context(), err)
|
||||
}
|
||||
p.Printf("import %s\n", t.Value)
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) parseTemplateCode() error {
|
||||
t, err := expectTagContents(p.s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err = validateTemplateCode(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid code at %s: %s", p.s.Context(), err)
|
||||
}
|
||||
p.Printf("%s\n", t.Value)
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) parseFuncCode() error {
|
||||
t, err := expectTagContents(p.s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err = validateFuncCode(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid code at %s: %s", p.s.Context(), err)
|
||||
}
|
||||
p.Printf("%s\n", t.Value)
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) parseOutputTag(tagNameStr string, prec int) error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if err = validateOutputTagValue(t.Value); err != nil {
|
||||
return fmt.Errorf("invalid output tag value at %s: %s", s.Context(), err)
|
||||
}
|
||||
filter := "N"
|
||||
switch tagNameStr {
|
||||
case "s", "v", "q", "z", "j", "sz", "qz", "jz":
|
||||
filter = "E"
|
||||
}
|
||||
if strings.HasSuffix(tagNameStr, "=") {
|
||||
tagNameStr = tagNameStr[:len(tagNameStr)-1]
|
||||
}
|
||||
if tagNameStr == "f" && prec >= 0 {
|
||||
p.Printf("qw%s.N().FPrec(%s, %d)", mangleSuffix, t.Value, prec)
|
||||
} else {
|
||||
tagNameStr = strings.ToUpper(tagNameStr)
|
||||
p.Printf("qw%s.%s().%s(%s)", mangleSuffix, filter, tagNameStr, t.Value)
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) parseOutputFunc(tagNameStr string) error {
|
||||
s := p.s
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
f, err := parseFuncCall(t.Value)
|
||||
if err != nil {
|
||||
return fmt.Errorf("error at %s: %s", s.Context(), err)
|
||||
}
|
||||
filter := "N"
|
||||
tagNameStr = tagNameStr[1:]
|
||||
if strings.HasSuffix(tagNameStr, "h") {
|
||||
tagNameStr = tagNameStr[:len(tagNameStr)-1]
|
||||
switch tagNameStr {
|
||||
case "", "q", "j":
|
||||
filter = "E"
|
||||
}
|
||||
}
|
||||
|
||||
if len(tagNameStr) > 0 || filter == "E" {
|
||||
tagNameStr = strings.ToUpper(tagNameStr)
|
||||
p.Printf("{")
|
||||
p.Printf("qb%s := qt%s.AcquireByteBuffer()", mangleSuffix, mangleSuffix)
|
||||
p.Printf("%s", f.CallWrite("qb"+mangleSuffix))
|
||||
p.Printf("qw%s.%s().%sZ(qb%s.B)", mangleSuffix, filter, tagNameStr, mangleSuffix)
|
||||
p.Printf("qt%s.ReleaseByteBuffer(qb%s)", mangleSuffix, mangleSuffix)
|
||||
p.Printf("}")
|
||||
} else {
|
||||
p.Printf("%s", f.CallStream("qw"+mangleSuffix))
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
func (p *parser) emitText(text []byte) {
|
||||
for len(text) > 0 {
|
||||
n := bytes.IndexByte(text, '`')
|
||||
if n < 0 {
|
||||
p.Printf("qw%s.N().S(`%s`)", mangleSuffix, text)
|
||||
return
|
||||
}
|
||||
p.Printf("qw%s.N().S(`%s`)", mangleSuffix, text[:n])
|
||||
p.Printf("qw%s.N().S(\"`\")", mangleSuffix)
|
||||
text = text[n+1:]
|
||||
}
|
||||
}
|
||||
|
||||
func (p *parser) emitFuncStart(f *funcType) {
|
||||
p.Printf("func %s {", f.DefStream("qw"+mangleSuffix))
|
||||
p.prefix = "\t"
|
||||
}
|
||||
|
||||
func (p *parser) emitFuncEnd(f *funcType) {
|
||||
p.prefix = ""
|
||||
p.Printf("}\n")
|
||||
|
||||
p.Printf("func %s {", f.DefWrite("qq"+mangleSuffix))
|
||||
p.prefix = "\t"
|
||||
p.Printf("qw%s := qt%s.AcquireWriter(qq%s)", mangleSuffix, mangleSuffix, mangleSuffix)
|
||||
p.Printf("%s", f.CallStream("qw"+mangleSuffix))
|
||||
p.Printf("qt%s.ReleaseWriter(qw%s)", mangleSuffix, mangleSuffix)
|
||||
p.prefix = ""
|
||||
p.Printf("}\n")
|
||||
|
||||
p.Printf("func %s {", f.DefString())
|
||||
p.prefix = "\t"
|
||||
p.Printf("qb%s := qt%s.AcquireByteBuffer()", mangleSuffix, mangleSuffix)
|
||||
p.Printf("%s", f.CallWrite("qb"+mangleSuffix))
|
||||
p.Printf("qs%s := string(qb%s.B)", mangleSuffix, mangleSuffix)
|
||||
p.Printf("qt%s.ReleaseByteBuffer(qb%s)", mangleSuffix, mangleSuffix)
|
||||
p.Printf("return qs%s", mangleSuffix)
|
||||
p.prefix = ""
|
||||
p.Printf("}\n")
|
||||
}
|
||||
|
||||
func (p *parser) Printf(format string, args ...interface{}) {
|
||||
if p.skipOutputDepth > 0 {
|
||||
return
|
||||
}
|
||||
w := p.w
|
||||
if !p.skipLineComments {
|
||||
// line comments are required to start at the beginning of the line
|
||||
p.s.WriteLineComment(w)
|
||||
}
|
||||
fmt.Fprintf(w, "%s", p.prefix)
|
||||
fmt.Fprintf(w, format, args...)
|
||||
fmt.Fprintf(w, "\n")
|
||||
}
|
||||
|
||||
func skipTagContents(s *scanner) error {
|
||||
tagName := string(s.Token().Value)
|
||||
t, err := expectTagContents(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
if len(t.Value) > 0 {
|
||||
return fmt.Errorf("unexpected extra value after %s: %q at %s", tagName, t.Value, s.Context())
|
||||
}
|
||||
return err
|
||||
}
|
||||
|
||||
func expectTagContents(s *scanner) (*token, error) {
|
||||
return expectToken(s, tagContents)
|
||||
}
|
||||
|
||||
func expectToken(s *scanner, id int) (*token, error) {
|
||||
if !s.Next() {
|
||||
return nil, fmt.Errorf("cannot find token %s: %v", tokenIDToStr(id), s.LastError())
|
||||
}
|
||||
t := s.Token()
|
||||
if t.ID != id {
|
||||
return nil, fmt.Errorf("unexpected token found %s. Expecting %s at %s", t, tokenIDToStr(id), s.Context())
|
||||
}
|
||||
return t, nil
|
||||
}
|
||||
|
||||
func validateOutputTagValue(stmt []byte) error {
|
||||
exprStr := string(stmt)
|
||||
_, err := goparser.ParseExpr(exprStr)
|
||||
return err
|
||||
}
|
||||
|
||||
func validateForStmt(stmt []byte) error {
|
||||
exprStr := fmt.Sprintf("func () { for %s {} }", stmt)
|
||||
_, err := goparser.ParseExpr(exprStr)
|
||||
return err
|
||||
}
|
||||
|
||||
func validateIfStmt(stmt []byte) error {
|
||||
exprStr := fmt.Sprintf("func () { if %s {} }", stmt)
|
||||
_, err := goparser.ParseExpr(exprStr)
|
||||
return err
|
||||
}
|
||||
|
||||
func validateSwitchStmt(stmt []byte) error {
|
||||
exprStr := fmt.Sprintf("func () { switch %s {} }", stmt)
|
||||
_, err := goparser.ParseExpr(exprStr)
|
||||
return err
|
||||
}
|
||||
|
||||
func validateCaseStmt(switchValue string, stmt []byte) error {
|
||||
exprStr := fmt.Sprintf("func () { switch %s {case %s:} }", switchValue, stmt)
|
||||
_, err := goparser.ParseExpr(exprStr)
|
||||
return err
|
||||
}
|
||||
|
||||
func validateFuncCode(code []byte) error {
|
||||
exprStr := fmt.Sprintf("func () { for { %s\n } }", code)
|
||||
_, err := goparser.ParseExpr(exprStr)
|
||||
return err
|
||||
}
|
||||
|
||||
func validateTemplateCode(code []byte) error {
|
||||
codeStr := fmt.Sprintf("package foo\nvar _ = a\n%s", code)
|
||||
fset := gotoken.NewFileSet()
|
||||
_, err := goparser.ParseFile(fset, "", codeStr, 0)
|
||||
return err
|
||||
}
|
||||
|
||||
func validatePackageName(code []byte) error {
|
||||
codeStr := fmt.Sprintf("package %s", code)
|
||||
fset := gotoken.NewFileSet()
|
||||
_, err := goparser.ParseFile(fset, "", codeStr, 0)
|
||||
return err
|
||||
}
|
||||
|
||||
func validateImport(code []byte) error {
|
||||
codeStr := fmt.Sprintf("package foo\nimport %s", code)
|
||||
fset := gotoken.NewFileSet()
|
||||
f, err := goparser.ParseFile(fset, "", codeStr, 0)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
for _, d := range f.Decls {
|
||||
gd, ok := d.(*ast.GenDecl)
|
||||
if !ok {
|
||||
return fmt.Errorf("unexpected code found: %T. Expecting ast.GenDecl", d)
|
||||
}
|
||||
for _, s := range gd.Specs {
|
||||
if _, ok := s.(*ast.ImportSpec); !ok {
|
||||
return fmt.Errorf("unexpected code found: %T. Expecting ast.ImportSpec", s)
|
||||
}
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
467
vendor/github.com/valyala/quicktemplate/parser/scanner.go
generated
vendored
467
vendor/github.com/valyala/quicktemplate/parser/scanner.go
generated
vendored
@@ -1,467 +0,0 @@
|
||||
package parser
|
||||
|
||||
import (
|
||||
"bufio"
|
||||
"bytes"
|
||||
"fmt"
|
||||
"io"
|
||||
"regexp"
|
||||
"strings"
|
||||
)
|
||||
|
||||
// token ids
|
||||
const (
|
||||
text = iota
|
||||
tagName
|
||||
tagContents
|
||||
)
|
||||
|
||||
var tokenStrMap = map[int]string{
|
||||
text: "text",
|
||||
tagName: "tagName",
|
||||
tagContents: "tagContents",
|
||||
}
|
||||
|
||||
func tokenIDToStr(id int) string {
|
||||
str := tokenStrMap[id]
|
||||
if str == "" {
|
||||
panic(fmt.Sprintf("unknown tokenID=%d", id))
|
||||
}
|
||||
return str
|
||||
}
|
||||
|
||||
type token struct {
|
||||
ID int
|
||||
Value []byte
|
||||
|
||||
line int
|
||||
pos int
|
||||
}
|
||||
|
||||
func (t *token) init(id, line, pos int) {
|
||||
t.ID = id
|
||||
t.Value = t.Value[:0]
|
||||
|
||||
t.line = line
|
||||
t.pos = pos
|
||||
}
|
||||
|
||||
func (t *token) String() string {
|
||||
return fmt.Sprintf("Token %q, value %q", tokenIDToStr(t.ID), t.Value)
|
||||
}
|
||||
|
||||
type scanner struct {
|
||||
r *bufio.Reader
|
||||
t token
|
||||
c byte
|
||||
err error
|
||||
|
||||
filePath string
|
||||
|
||||
line int
|
||||
lineStr []byte
|
||||
|
||||
nextTokenID int
|
||||
|
||||
capture bool
|
||||
capturedValue []byte
|
||||
|
||||
collapseSpaceDepth int
|
||||
stripSpaceDepth int
|
||||
stripToNewLine bool
|
||||
rewind bool
|
||||
}
|
||||
|
||||
var tailOfLine = regexp.MustCompile(`^[[:blank:]]*(?:\r*\n)?`)
|
||||
var prevBlank = regexp.MustCompile(`[[:blank:]]+$`)
|
||||
|
||||
func newScanner(r io.Reader, filePath string) *scanner {
|
||||
// Substitute backslashes with forward slashes in filePath
|
||||
// for the sake of consistency on different platforms (windows, linux).
|
||||
// See https://github.com/valyala/quicktemplate/issues/62.
|
||||
filePath = strings.Replace(filePath, "\\", "/", -1)
|
||||
|
||||
return &scanner{
|
||||
r: bufio.NewReader(r),
|
||||
filePath: filePath,
|
||||
}
|
||||
}
|
||||
|
||||
func (s *scanner) Rewind() {
|
||||
if s.rewind {
|
||||
panic("BUG: duplicate Rewind call")
|
||||
}
|
||||
s.rewind = true
|
||||
}
|
||||
|
||||
func (s *scanner) Next() bool {
|
||||
if s.rewind {
|
||||
s.rewind = false
|
||||
return true
|
||||
}
|
||||
|
||||
for {
|
||||
if !s.scanToken() {
|
||||
return false
|
||||
}
|
||||
switch s.t.ID {
|
||||
case text:
|
||||
if s.stripToNewLine {
|
||||
s.t.Value = tailOfLine.ReplaceAll(s.t.Value, nil)
|
||||
s.stripToNewLine = false
|
||||
}
|
||||
if len(s.t.Value) == 0 {
|
||||
// skip empty text
|
||||
continue
|
||||
}
|
||||
case tagName:
|
||||
switch string(s.t.Value) {
|
||||
case "comment":
|
||||
if !s.skipComment() {
|
||||
return false
|
||||
}
|
||||
continue
|
||||
case "plain":
|
||||
if !s.readPlain() {
|
||||
return false
|
||||
}
|
||||
if len(s.t.Value) == 0 {
|
||||
// skip empty text
|
||||
continue
|
||||
}
|
||||
case "collapsespace":
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
s.collapseSpaceDepth++
|
||||
continue
|
||||
case "stripspace":
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
s.stripSpaceDepth++
|
||||
continue
|
||||
case "endcollapsespace":
|
||||
if s.collapseSpaceDepth == 0 {
|
||||
s.err = fmt.Errorf("endcollapsespace tag found without the corresponding collapsespace tag")
|
||||
return false
|
||||
}
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
s.collapseSpaceDepth--
|
||||
continue
|
||||
case "endstripspace":
|
||||
if s.stripSpaceDepth == 0 {
|
||||
s.err = fmt.Errorf("endstripspace tag found without the corresponding stripspace tag")
|
||||
return false
|
||||
}
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
s.stripSpaceDepth--
|
||||
continue
|
||||
case "space":
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
s.t.init(text, s.t.line, s.t.pos)
|
||||
s.t.Value = append(s.t.Value[:0], ' ')
|
||||
return true
|
||||
case "newline":
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
s.t.init(text, s.t.line, s.t.pos)
|
||||
s.t.Value = append(s.t.Value[:0], '\n')
|
||||
return true
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
func (s *scanner) readPlain() bool {
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
startLine := s.line
|
||||
startPos := s.pos()
|
||||
s.startCapture()
|
||||
ok := s.skipUntilTag("endplain")
|
||||
v := s.stopCapture()
|
||||
s.t.init(text, startLine, startPos)
|
||||
if ok {
|
||||
n := bytes.LastIndex(v, strTagOpen)
|
||||
v = v[:n]
|
||||
s.t.Value = append(s.t.Value[:0], v...)
|
||||
}
|
||||
return ok
|
||||
}
|
||||
|
||||
var strTagOpen = []byte("{%")
|
||||
|
||||
func (s *scanner) skipComment() bool {
|
||||
if !s.readTagContents() {
|
||||
return false
|
||||
}
|
||||
return s.skipUntilTag("endcomment")
|
||||
}
|
||||
|
||||
func (s *scanner) skipUntilTag(tagName string) bool {
|
||||
ok := false
|
||||
for {
|
||||
if !s.nextByte() {
|
||||
break
|
||||
}
|
||||
if s.c != '{' {
|
||||
continue
|
||||
}
|
||||
if !s.nextByte() {
|
||||
break
|
||||
}
|
||||
if s.c != '%' {
|
||||
s.unreadByte('~')
|
||||
continue
|
||||
}
|
||||
ok = s.readTagName()
|
||||
s.nextTokenID = text
|
||||
if !ok {
|
||||
s.err = nil
|
||||
continue
|
||||
}
|
||||
if string(s.t.Value) == tagName {
|
||||
ok = s.readTagContents()
|
||||
break
|
||||
}
|
||||
}
|
||||
if !ok {
|
||||
s.err = fmt.Errorf("cannot find %q tag: %s", tagName, s.err)
|
||||
}
|
||||
return ok
|
||||
}
|
||||
|
||||
func (s *scanner) scanToken() bool {
|
||||
switch s.nextTokenID {
|
||||
case text:
|
||||
return s.readText()
|
||||
case tagName:
|
||||
return s.readTagName()
|
||||
case tagContents:
|
||||
return s.readTagContents()
|
||||
default:
|
||||
panic(fmt.Sprintf("BUG: unknown nextTokenID %d", s.nextTokenID))
|
||||
}
|
||||
}
|
||||
|
||||
func (s *scanner) readText() bool {
|
||||
s.t.init(text, s.line, s.pos())
|
||||
ok := false
|
||||
for {
|
||||
if !s.nextByte() {
|
||||
ok = (len(s.t.Value) > 0)
|
||||
break
|
||||
}
|
||||
if s.c != '{' {
|
||||
s.appendByte()
|
||||
continue
|
||||
}
|
||||
if !s.nextByte() {
|
||||
s.appendByte()
|
||||
ok = true
|
||||
break
|
||||
}
|
||||
if s.c == '%' {
|
||||
s.nextTokenID = tagName
|
||||
ok = true
|
||||
if !s.nextByte() {
|
||||
s.appendByte()
|
||||
break
|
||||
}
|
||||
if s.c != '-' {
|
||||
s.unreadByte(s.c)
|
||||
break
|
||||
}
|
||||
s.t.Value = prevBlank.ReplaceAll(s.t.Value, nil)
|
||||
break
|
||||
}
|
||||
s.unreadByte('{')
|
||||
s.appendByte()
|
||||
}
|
||||
if s.stripSpaceDepth > 0 {
|
||||
s.t.Value = stripSpace(s.t.Value)
|
||||
} else if s.collapseSpaceDepth > 0 {
|
||||
s.t.Value = collapseSpace(s.t.Value)
|
||||
}
|
||||
return ok
|
||||
}
|
||||
|
||||
func (s *scanner) readTagName() bool {
|
||||
s.skipSpace()
|
||||
s.t.init(tagName, s.line, s.pos())
|
||||
for {
|
||||
if s.isSpace() || s.c == '%' {
|
||||
if s.c == '%' {
|
||||
s.unreadByte('~')
|
||||
}
|
||||
s.nextTokenID = tagContents
|
||||
return true
|
||||
}
|
||||
if (s.c >= 'a' && s.c <= 'z') || (s.c >= 'A' && s.c <= 'Z') || (s.c >= '0' && s.c <= '9') || s.c == '=' || s.c == '.' {
|
||||
s.appendByte()
|
||||
if !s.nextByte() {
|
||||
return false
|
||||
}
|
||||
continue
|
||||
}
|
||||
if s.c == '-' {
|
||||
s.unreadByte(s.c)
|
||||
s.nextTokenID = tagContents
|
||||
return true
|
||||
}
|
||||
s.err = fmt.Errorf("unexpected character: '%c'", s.c)
|
||||
s.unreadByte('~')
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
func (s *scanner) readTagContents() bool {
|
||||
s.skipSpace()
|
||||
s.t.init(tagContents, s.line, s.pos())
|
||||
for {
|
||||
if s.c != '%' {
|
||||
s.appendByte()
|
||||
if !s.nextByte() {
|
||||
return false
|
||||
}
|
||||
continue
|
||||
}
|
||||
if !s.nextByte() {
|
||||
s.appendByte()
|
||||
return false
|
||||
}
|
||||
if s.c == '}' {
|
||||
if bytes.HasSuffix(s.t.Value, []byte("-")) {
|
||||
s.t.Value = s.t.Value[:len(s.t.Value)-1]
|
||||
s.stripToNewLine = true
|
||||
}
|
||||
s.nextTokenID = text
|
||||
s.t.Value = stripTrailingSpace(s.t.Value)
|
||||
return true
|
||||
}
|
||||
s.unreadByte('%')
|
||||
s.appendByte()
|
||||
if !s.nextByte() {
|
||||
return false
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func (s *scanner) skipSpace() {
|
||||
for s.nextByte() && s.isSpace() {
|
||||
}
|
||||
}
|
||||
|
||||
func (s *scanner) isSpace() bool {
|
||||
return isSpace(s.c)
|
||||
}
|
||||
|
||||
func (s *scanner) nextByte() bool {
|
||||
if s.err != nil {
|
||||
return false
|
||||
}
|
||||
c, err := s.r.ReadByte()
|
||||
if err != nil {
|
||||
if err == io.EOF {
|
||||
err = io.ErrUnexpectedEOF
|
||||
}
|
||||
s.err = err
|
||||
return false
|
||||
}
|
||||
if c == '\n' {
|
||||
s.line++
|
||||
s.lineStr = s.lineStr[:0]
|
||||
} else {
|
||||
s.lineStr = append(s.lineStr, c)
|
||||
}
|
||||
s.c = c
|
||||
if s.capture {
|
||||
s.capturedValue = append(s.capturedValue, c)
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
func (s *scanner) startCapture() {
|
||||
s.capture = true
|
||||
s.capturedValue = s.capturedValue[:0]
|
||||
}
|
||||
|
||||
func (s *scanner) stopCapture() []byte {
|
||||
s.capture = false
|
||||
v := s.capturedValue
|
||||
s.capturedValue = s.capturedValue[:0]
|
||||
return v
|
||||
}
|
||||
|
||||
func (s *scanner) Token() *token {
|
||||
return &s.t
|
||||
}
|
||||
|
||||
func (s *scanner) LastError() error {
|
||||
if s.err == nil {
|
||||
return nil
|
||||
}
|
||||
if s.err == io.ErrUnexpectedEOF && s.t.ID == text {
|
||||
if s.collapseSpaceDepth > 0 {
|
||||
return fmt.Errorf("missing endcollapsespace tag at %s", s.Context())
|
||||
}
|
||||
if s.stripSpaceDepth > 0 {
|
||||
return fmt.Errorf("missing endstripspace tag at %s", s.Context())
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
return fmt.Errorf("error when reading %s at %s: %s",
|
||||
tokenIDToStr(s.t.ID), s.Context(), s.err)
|
||||
}
|
||||
|
||||
func (s *scanner) appendByte() {
|
||||
s.t.Value = append(s.t.Value, s.c)
|
||||
}
|
||||
|
||||
func (s *scanner) unreadByte(c byte) {
|
||||
if err := s.r.UnreadByte(); err != nil {
|
||||
panic(fmt.Sprintf("BUG: bufio.Reader.UnreadByte returned non-nil error: %s", err))
|
||||
}
|
||||
if s.capture {
|
||||
s.capturedValue = s.capturedValue[:len(s.capturedValue)-1]
|
||||
}
|
||||
if s.c == '\n' {
|
||||
s.line--
|
||||
s.lineStr = s.lineStr[:0] // TODO: use correct line
|
||||
} else {
|
||||
s.lineStr = s.lineStr[:len(s.lineStr)-1]
|
||||
}
|
||||
s.c = c
|
||||
}
|
||||
|
||||
func (s *scanner) pos() int {
|
||||
return len(s.lineStr)
|
||||
}
|
||||
|
||||
func (s *scanner) Context() string {
|
||||
t := s.Token()
|
||||
return fmt.Sprintf("file %q, line %d, pos %d, token %s, last line %s",
|
||||
s.filePath, t.line+1, t.pos, snippet(t.Value), snippet(s.lineStr))
|
||||
}
|
||||
|
||||
func (s *scanner) WriteLineComment(w io.Writer) {
|
||||
fmt.Fprintf(w, "//line %s:%d\n", s.filePath, s.t.line+1)
|
||||
}
|
||||
|
||||
func snippet(s []byte) string {
|
||||
if len(s) <= 40 {
|
||||
return fmt.Sprintf("%q", s)
|
||||
}
|
||||
return fmt.Sprintf("%q ... %q", s[:20], s[len(s)-20:])
|
||||
}
|
||||
96
vendor/github.com/valyala/quicktemplate/parser/util.go
generated
vendored
96
vendor/github.com/valyala/quicktemplate/parser/util.go
generated
vendored
@@ -1,96 +0,0 @@
|
||||
package parser
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"errors"
|
||||
"io/ioutil"
|
||||
"path/filepath"
|
||||
"unicode"
|
||||
)
|
||||
|
||||
// mangleSuffix is used for mangling quicktemplate-specific names
|
||||
// in the generated code, so they don't clash with user-provided names.
|
||||
const mangleSuffix = "422016"
|
||||
|
||||
func stripLeadingSpace(b []byte) []byte {
|
||||
for len(b) > 0 && isSpace(b[0]) {
|
||||
b = b[1:]
|
||||
}
|
||||
return b
|
||||
}
|
||||
|
||||
func stripTrailingSpace(b []byte) []byte {
|
||||
for len(b) > 0 && isSpace(b[len(b)-1]) {
|
||||
b = b[:len(b)-1]
|
||||
}
|
||||
return b
|
||||
}
|
||||
|
||||
func collapseSpace(b []byte) []byte {
|
||||
return stripSpaceExt(b, true)
|
||||
}
|
||||
|
||||
func stripSpace(b []byte) []byte {
|
||||
return stripSpaceExt(b, false)
|
||||
}
|
||||
|
||||
func stripSpaceExt(b []byte, isCollapse bool) []byte {
|
||||
if len(b) == 0 {
|
||||
return b
|
||||
}
|
||||
|
||||
var dst []byte
|
||||
if isCollapse && isSpace(b[0]) {
|
||||
dst = append(dst, ' ')
|
||||
}
|
||||
isLastSpace := isSpace(b[len(b)-1])
|
||||
for len(b) > 0 {
|
||||
n := bytes.IndexByte(b, '\n')
|
||||
if n < 0 {
|
||||
n = len(b)
|
||||
}
|
||||
z := b[:n]
|
||||
if n == len(b) {
|
||||
b = b[n:]
|
||||
} else {
|
||||
b = b[n+1:]
|
||||
}
|
||||
z = stripLeadingSpace(z)
|
||||
z = stripTrailingSpace(z)
|
||||
if len(z) == 0 {
|
||||
continue
|
||||
}
|
||||
dst = append(dst, z...)
|
||||
if isCollapse {
|
||||
dst = append(dst, ' ')
|
||||
}
|
||||
}
|
||||
if isCollapse && !isLastSpace && len(dst) > 0 {
|
||||
dst = dst[:len(dst)-1]
|
||||
}
|
||||
return dst
|
||||
}
|
||||
|
||||
func isSpace(c byte) bool {
|
||||
return unicode.IsSpace(rune(c))
|
||||
}
|
||||
|
||||
func isUpper(c byte) bool {
|
||||
return unicode.IsUpper(rune(c))
|
||||
}
|
||||
|
||||
func readFile(cwd, filename string) ([]byte, error) {
|
||||
if len(filename) == 0 {
|
||||
return nil, errors.New("filename cannot be empty")
|
||||
}
|
||||
if filename[0] != '/' {
|
||||
cwdAbs, err := filepath.Abs(cwd)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
dir, _ := filepath.Split(cwdAbs)
|
||||
filename = filepath.Join(dir, filename)
|
||||
}
|
||||
|
||||
return ioutil.ReadFile(filename)
|
||||
}
|
||||
22
vendor/github.com/valyala/quicktemplate/qtc/LICENSE
generated
vendored
22
vendor/github.com/valyala/quicktemplate/qtc/LICENSE
generated
vendored
@@ -1,22 +0,0 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2016 Aliaksandr Valialkin, VertaMedia
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
|
||||
33
vendor/github.com/valyala/quicktemplate/qtc/README.md
generated
vendored
33
vendor/github.com/valyala/quicktemplate/qtc/README.md
generated
vendored
@@ -1,33 +0,0 @@
|
||||
# qtc
|
||||
|
||||
Template compiler (converter) for [quicktemplate](https://github.com/valyala/quicktemplate).
|
||||
Converts quicktemplate files into Go code. By default these files
|
||||
have `.qtpl` extension.
|
||||
|
||||
# Usage
|
||||
|
||||
```
|
||||
$ go get -u github.com/valyala/quicktemplate/qtc
|
||||
$ qtc -h
|
||||
```
|
||||
|
||||
`qtc` may be called either directly or via [go generate](https://blog.golang.org/generate).
|
||||
The latter case is preffered. Just put the following line near the `main` function:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
//go:generate qtc -dir=path/to/directory/with/templates
|
||||
|
||||
func main() {
|
||||
// main code here
|
||||
}
|
||||
```
|
||||
|
||||
Then run `go generate` whenever you need re-generating template code.
|
||||
Directory with templates may contain arbirary number of subdirectories -
|
||||
`qtc` generates template code recursively for each subdirectory.
|
||||
|
||||
Directories with templates may also contain arbitrary `.go` files - contents
|
||||
of these files may be used inside templates. Such Go files usually contain
|
||||
various helper functions and structs.
|
||||
174
vendor/github.com/valyala/quicktemplate/qtc/main.go
generated
vendored
174
vendor/github.com/valyala/quicktemplate/qtc/main.go
generated
vendored
@@ -1,174 +0,0 @@
|
||||
// Command qtc is a compiler for quicktemplate files.
|
||||
//
|
||||
// See https://github.com/valyala/quicktemplate/qtc for details.
|
||||
package main
|
||||
|
||||
import (
|
||||
"flag"
|
||||
"go/format"
|
||||
"io/ioutil"
|
||||
"log"
|
||||
"os"
|
||||
"path/filepath"
|
||||
"sort"
|
||||
"strings"
|
||||
|
||||
"github.com/valyala/quicktemplate/parser"
|
||||
)
|
||||
|
||||
var (
|
||||
dir = flag.String("dir", ".", "Path to directory with template files to compile. "+
|
||||
"Only files with ext extension are compiled. See ext flag for details.\n"+
|
||||
"The compiler recursively processes all the subdirectories.\n"+
|
||||
"Compiled template files are placed near the original file with .go extension added.")
|
||||
|
||||
file = flag.String("file", "", "Path to template file to compile.\n"+
|
||||
"Flags -dir and -ext are ignored if file is set.\n"+
|
||||
"The compiled file will be placed near the original file with .go extension added.")
|
||||
ext = flag.String("ext", "qtpl", "Only files with this extension are compiled")
|
||||
skipLineComments = flag.Bool("skipLineComments", false, "Don't write line comments")
|
||||
)
|
||||
|
||||
var logger = log.New(os.Stderr, "qtc: ", log.LstdFlags)
|
||||
|
||||
var filesCompiled int
|
||||
|
||||
func main() {
|
||||
flag.Parse()
|
||||
|
||||
if len(*file) > 0 {
|
||||
compileSingleFile(*file)
|
||||
return
|
||||
}
|
||||
|
||||
if len(*ext) == 0 {
|
||||
logger.Fatalf("ext cannot be empty")
|
||||
}
|
||||
if len(*dir) == 0 {
|
||||
*dir = "."
|
||||
}
|
||||
if (*ext)[0] != '.' {
|
||||
*ext = "." + *ext
|
||||
}
|
||||
|
||||
logger.Printf("Compiling *%s template files in directory %q", *ext, *dir)
|
||||
compileDir(*dir)
|
||||
logger.Printf("Total files compiled: %d", filesCompiled)
|
||||
}
|
||||
|
||||
func compileSingleFile(filename string) {
|
||||
fi, err := os.Stat(filename)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot stat file %q: %s", filename, err)
|
||||
}
|
||||
if fi.IsDir() {
|
||||
logger.Fatalf("cannot compile directory %q. Use -dir flag", filename)
|
||||
}
|
||||
compileFile(filename)
|
||||
}
|
||||
|
||||
func compileDir(path string) {
|
||||
fi, err := os.Stat(path)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot compile files in %q: %s", path, err)
|
||||
}
|
||||
if !fi.IsDir() {
|
||||
logger.Fatalf("cannot compile files in %q: it is not directory", path)
|
||||
}
|
||||
d, err := os.Open(path)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot compile files in %q: %s", path, err)
|
||||
}
|
||||
defer d.Close()
|
||||
|
||||
fis, err := d.Readdir(-1)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot read files in %q: %s", path, err)
|
||||
}
|
||||
|
||||
var names []string
|
||||
for _, fi = range fis {
|
||||
name := fi.Name()
|
||||
if name == "." || name == ".." {
|
||||
continue
|
||||
}
|
||||
if !fi.IsDir() {
|
||||
names = append(names, name)
|
||||
} else {
|
||||
subPath := filepath.Join(path, name)
|
||||
compileDir(subPath)
|
||||
}
|
||||
}
|
||||
sort.Strings(names)
|
||||
|
||||
for _, name := range names {
|
||||
if strings.HasSuffix(name, *ext) {
|
||||
filename := filepath.Join(path, name)
|
||||
compileFile(filename)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func compileFile(infile string) {
|
||||
outfile := infile + ".go"
|
||||
logger.Printf("Compiling %q to %q...", infile, outfile)
|
||||
|
||||
inf, err := os.Open(infile)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot open file %q: %s", infile, err)
|
||||
}
|
||||
|
||||
tmpfile := outfile + ".tmp"
|
||||
outf, err := os.Create(tmpfile)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot create file %q: %s", tmpfile, err)
|
||||
}
|
||||
|
||||
packageName, err := getPackageName(infile)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot determine package name for %q: %s", infile, err)
|
||||
}
|
||||
|
||||
parseFunc := parser.Parse
|
||||
if *skipLineComments {
|
||||
parseFunc = parser.ParseNoLineComments
|
||||
}
|
||||
|
||||
if err = parseFunc(outf, inf, infile, packageName); err != nil {
|
||||
logger.Fatalf("error when parsing file %q: %s", infile, err)
|
||||
}
|
||||
|
||||
if err = outf.Close(); err != nil {
|
||||
logger.Fatalf("error when closing file %q: %s", tmpfile, err)
|
||||
}
|
||||
if err = inf.Close(); err != nil {
|
||||
logger.Fatalf("error when closing file %q: %s", infile, err)
|
||||
}
|
||||
|
||||
// prettify the output file
|
||||
uglyCode, err := ioutil.ReadFile(tmpfile)
|
||||
if err != nil {
|
||||
logger.Fatalf("cannot read file %q: %s", tmpfile, err)
|
||||
}
|
||||
prettyCode, err := format.Source(uglyCode)
|
||||
if err != nil {
|
||||
logger.Fatalf("error when formatting compiled code for %q: %s. See %q for details", infile, err, tmpfile)
|
||||
}
|
||||
if err = ioutil.WriteFile(outfile, prettyCode, 0666); err != nil {
|
||||
logger.Fatalf("error when writing file %q: %s", outfile, err)
|
||||
}
|
||||
if err = os.Remove(tmpfile); err != nil {
|
||||
logger.Fatalf("error when removing file %q: %s", tmpfile, err)
|
||||
}
|
||||
|
||||
filesCompiled++
|
||||
}
|
||||
|
||||
func getPackageName(filename string) (string, error) {
|
||||
filenameAbs, err := filepath.Abs(filename)
|
||||
if err != nil {
|
||||
return "", err
|
||||
}
|
||||
dir, _ := filepath.Split(filenameAbs)
|
||||
return filepath.Base(dir), nil
|
||||
}
|
||||
6
vendor/modules.txt
vendored
6
vendor/modules.txt
vendored
@@ -560,13 +560,9 @@ github.com/puzpuzpuz/xsync/v3
|
||||
# github.com/rivo/uniseg v0.4.7
|
||||
## explicit; go 1.18
|
||||
github.com/rivo/uniseg
|
||||
# github.com/rogpeppe/go-internal v1.14.1
|
||||
## explicit; go 1.23
|
||||
# github.com/russross/blackfriday/v2 v2.1.0
|
||||
## explicit
|
||||
github.com/russross/blackfriday/v2
|
||||
# github.com/spf13/pflag v1.0.6
|
||||
## explicit; go 1.12
|
||||
# github.com/stretchr/testify v1.10.0
|
||||
## explicit; go 1.17
|
||||
github.com/stretchr/testify/assert
|
||||
@@ -597,8 +593,6 @@ github.com/valyala/histogram
|
||||
# github.com/valyala/quicktemplate v1.8.0
|
||||
## explicit; go 1.17
|
||||
github.com/valyala/quicktemplate
|
||||
github.com/valyala/quicktemplate/parser
|
||||
github.com/valyala/quicktemplate/qtc
|
||||
# github.com/xrash/smetrics v0.0.0-20240521201337-686a1a2994c1
|
||||
## explicit; go 1.15
|
||||
github.com/xrash/smetrics
|
||||
|
||||
Reference in New Issue
Block a user